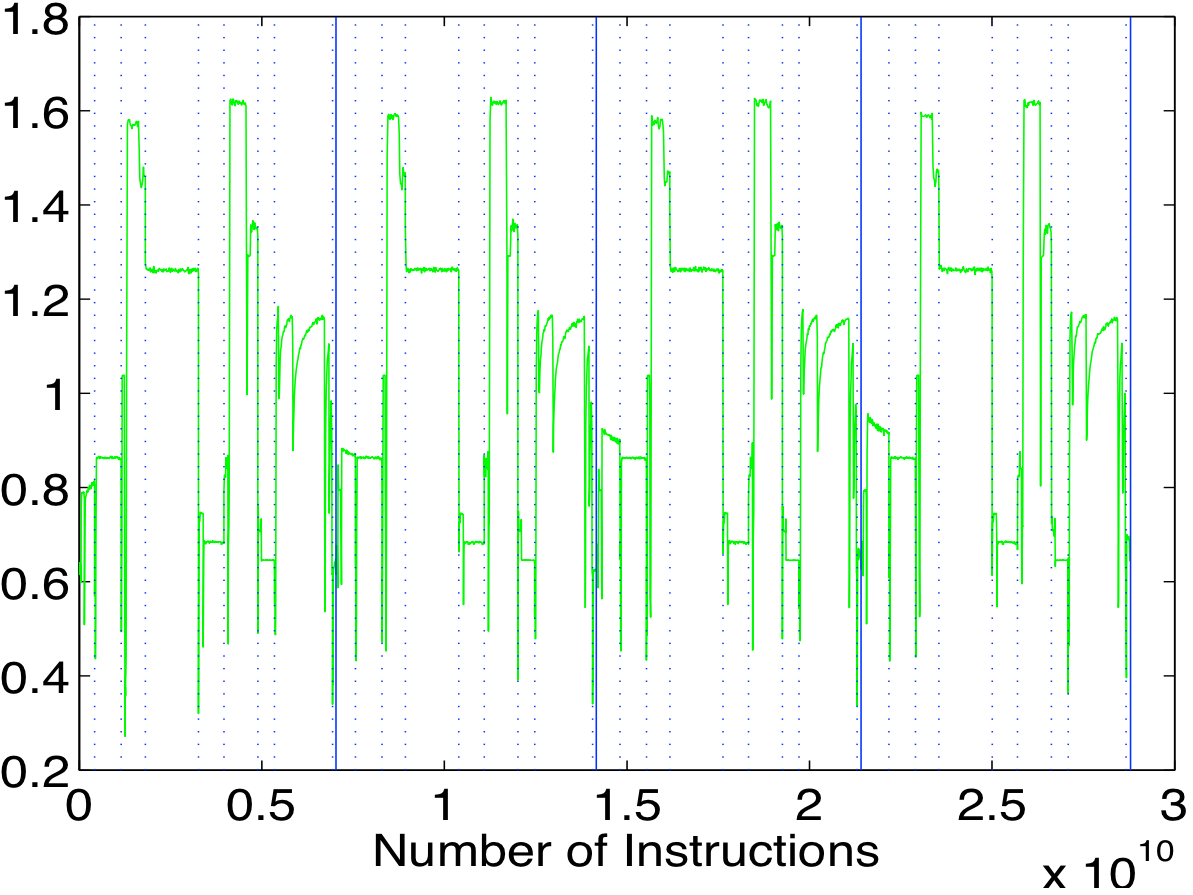
In this paper, Fang et. al. extended the notion of memory distance, e.g. reuse distances, to applying on the instruction space of a program, guiding feedback-directed optimization. Memory distance is a dynamic quantifiable distance in terms of memory references between two accesses to the same memory location. The use of memory distance is to predict the miss rates of instructions in a program. Using the miss rates, the author then identified the program’s critical instructions – the set of high miss instructions whose cumulative misses account for 95% of the L2 cache misses in the program – in both integer and floating-point programs. In addition, memory distance analysis is applied to memory disambiguation in out-of-order issue processors, using those distances to determine when a load may be speculated ahead of a preceding store.
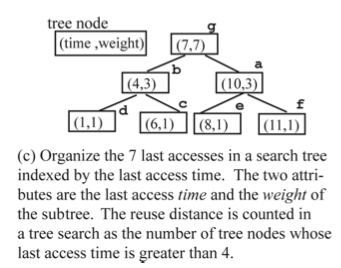
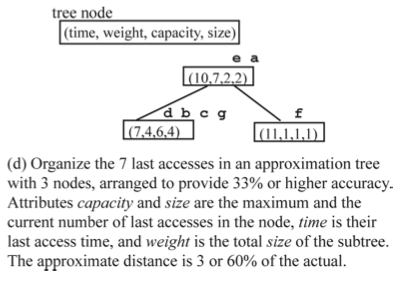
The authors define the notion of memory distance as any dynamic quantifiable distance in terms of memory references between two accesses to the same memory location. Reuse distance is thus a special case of memory distance. The contribution of the work is an algorithm to predict the reuse distance distribution and miss rate for each instruction. The major overhead is storage. For each instruction, a series of log-scale bins is maintained, each bin is attributed by min, max, mean, frequency (access count). The bins is the full reuse distance representation of an instruction. Adjacent bins can be merged to form a locality pattern .The locality pattern is approximated by a linear distribution of reuse distances. The locality patterns is
a compact representation of reuse distances. In order to use the training run’s reuse distance profiles to predict other run’s reuse distance, the authors also define the prediction coverage, (whether the instruction is present in test run if it was in training run) and prediction accuracy (whether the reuse distances in training runs are roughly match the reuse distances in test runs). The authors found that linearly merging bins into patterns improves the prediction accuracy.
Using reuse distances to predict miss rate is very straightforward. No conflict misses are modeled. Using per-instruction reuse distances to identify critical instructions is also easy to do. The authors found that critical instructions tend to have more diverse locality patterns than non-critical instructions. Critical instructions also tend to exhibit a higher percentage of non-constant patterns than non-critical instructions.
The authors introduce two new forms of memory distance – access distance and value distance – and explore the potential of using them to determine which loads in a program may be speculated. The access distance of a memory reference is the number of memory instructions between a store to and a load from the same address. The value distance of a reference is defined as the access distance of a load to the first store in a sequence of stores of the same value.
The intuition is for speculative execution, if a load is sufficiently far away from the previous store to the same address, the load will be a good speculative candidate. Access distance can be used to model this notion for speculation. When multiple successive stores to the same address write the same value, a subsequent load to that address may be safely moved prior to all of those stores except the first as long as the memory order violation detection hardware examines the values of loads and stores. Value distance can be used to model this effect.