Characterizing the memory performance of today’s diverse workloads is an important and challenging problem. Considering their bursty, irregular, and dynamic behavior along with limited available resource, achieving efficient and accurate characterization has been the focus of many research papers in the field.
Denning’s working set theory lead to the first abstraction for memory performance. Simply, extract the phases of a program and then compute the working set size of each program. With the development of caching memories, choosing the cache size became an important performance decision. This choice required a method that can approximate the program’s memory performance under different cache sizes; the miss ratio curve. However, at the time, the best practice for computing such a curve was Mattson’s original stack simulation algorithm, which required O(MN) time and O(M) space for a trace of N requests for M unique elements (a hash table is used for storing the last access times). An optimization using a balanced tree to maintain stack distances reduces the time complexity to O(N lg M), while it preserves the space cost.
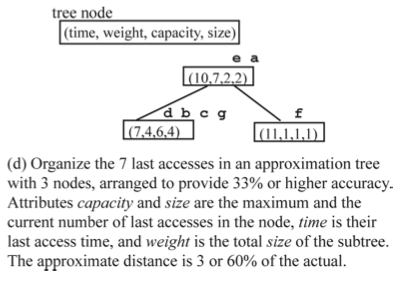
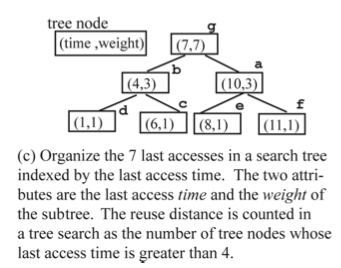 It looks like efforts on further reducing the costs fail when we target the exact hit ratio curve. Zhong et al. [1] proposed computing the approximate stack distances. They design a new data structure, called a scale tree and use that to approximate the reuse distance of every request with relative precision. They reduce the time complexity to O(N lg lg M) while requiring the O(M) space as before.
It looks like efforts on further reducing the costs fail when we target the exact hit ratio curve. Zhong et al. [1] proposed computing the approximate stack distances. They design a new data structure, called a scale tree and use that to approximate the reuse distance of every request with relative precision. They reduce the time complexity to O(N lg lg M) while requiring the O(M) space as before.
It turns out the problem of estimating the stack distances is closely related to the distinct elements problem: How many distinct elements are in a stream? This well-studied problem is also known as cardinality estimation and zero frequency moment estimation (F0 estimation). Here is the approximation version of the problem.
Given δ>0 and ε>0, and a sequence of elements with M distinct elements (M is unknown), give C such that |M-C| < εM with probability at least 1-δ.
It is natural to ask the question of “how much space and time is necessary or sufficient for any algorithm with such guarantee.” It turns out that if δ=0 or ε=0 then the space cost is Ω(M). However, if none of these cases happen then the optimal space bound is Ө(lg M + ε^2) [3]. Here is a simpler algorithm that achieves a multiplicative guarantee. These algorithms are alternatively called probabilistic counters.
“Let d be the smallest integer so that 2^d > n, and consider the members of N as elements of the finite field F = GF(2^d), which are represented by binary vectors of length d. Let a and b be two random members of F , chosen uniformly and independently. When a member a_i of the sequence A appears, compute z_i = a · a_i + b , where the product and addition are computed in the field F . Thus z_i is represented by a binary vector of length d. For any binary vector z, let r(z) denote the largest r so that the r rightmost bits of z are all 0 and put r_i = r(z_i). Let R be the maximum value of r_i, where the maximum is taken over all elements a_i of the sequence A. The output of the algorithm is Y = 2^R. ” (adopted from [4])
Recently, Wires et al. [2] have used these probabilistic counters to approximate the hit ratio curve and achieved sublinear space.
References:
[1] Yutao Zhong, Xipeng Shen, Chen Ding: Program locality analysis using reuse distance. ACM Trans. Program. Lang. Syst. 31(6) (2009)
[2] Jake Wires, Stephen Ingram, Zachary Drudi, Nicholas J. A. Harvey, Andrew Warfield: Characterizing Storage Workloads with Counter Stacks. OSDI 2014: 335-349
[3] Daniel M. Kane, Jelani Nelson, David P. Woodruff: An optimal algorithm for the distinct elements problem. PODS 2010: 41-52
[4] Noga Alon, Yossi Matias, Mario Szegedy: The Space Complexity of Approximating the Frequency Moments. J. Comput. Syst. Sci. 58(1): 137-147 (1999)
