Yesterday, on my way to the YMCA for my 1700-meter swim, AC on high in 100-degree (“heat dome” over 163 million people across central and eastern US), I was chatting about the story of Freon—invention, then ban.
Freon was invented for air conditioning in 1930 in Dayton, Ohio. The goal was to find a safe, non-toxic replacement for the dangerous refrigerants of the time, such as ammonia and sulfur dioxide. The compound was later known as Freon-12 or CFC-12. It quickly led to the widespread adoption of safe and efficient air conditioning, in vehicles and homes and businesses across the country and then the world.
In 1972, U.S. chemist Rowland at a conference heard the detection of CFC-11 in the air over the Atlantic. This sparked his curiosity: if these human-made chemicals were accumulating in the atmosphere, what ultimately happened to them? Working with his post-doc Molina, they knew CFCs, including Freon, were designed to be inert and non-soluble, meaning they wouldn’t break down in the lower atmosphere through rain or common chemical reactions. The only fate was to drift slowly up to the stratosphere, where intense ultraviolet light would break them apart, releasing highly reactive chlorine atoms. Their model showed a single chlorine atom could act as a catalyst, destroying tens of thousands of ozone molecules in a chain reaction.
The journal Nature published their paper on June 28, 1974. In September, they held a press conference to share their results, initiating advocacy for policy change. Over the next few years, their theory was confirmed by U.S. scientists, institutions and equipment. In 1975, National Oceanic and Atmospheric Administration (NOAA) used air samples collected by weather balloons at heights up to 17.4 miles and found that CFCs were reaching the stratosphere in the predicted amounts and were being broken down at the expected altitudes. NASA Jet Propulsion Laboratory used high-altitude U-2 spy planes and weather balloons to measure hydrochloric acid in the stratosphere and found higher concentrations at higher altitudes (a source of chlorine), which aligned perfectly with the Molina-Rowland theory.
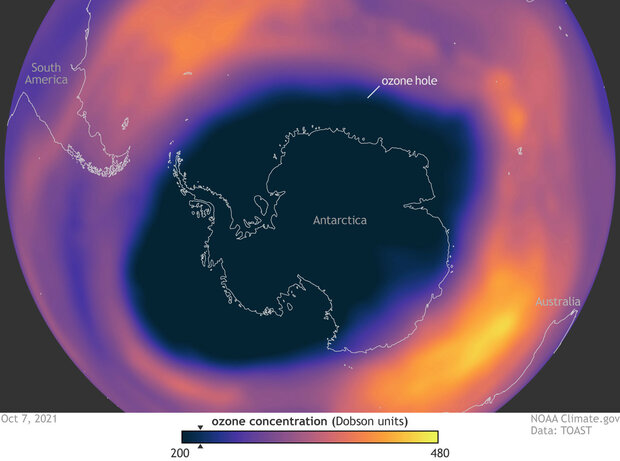
In October 1978, NASA launched Nimbus-7 satellite to carry equipment specifically designed to measure ozone: the Total Ozone Mapping Spectrometer (TOMS). It was groundbreaking because it could create daily global maps of total ozone, giving a bird’s-eye view of the ozone layer worldwide. When the British Antarctic Survey published in 1985 showing unexpectedly low ozone over Antarctica, the Nimbus-7 data became an essential independent check. In fact, TOMS recorded extremely low ozone values in 1983 and 1984, but the values were so far outside the expected range that the computer system flagged them as errors and filtered them out as “bad data.” After the British discovery was published, NASA scientists reviewed the archived TOMS data, reprocessed it without the erroneous low-value filter, and confirmed the findings. The satellite data showed that the dramatic thinning of the ozone layer over the Antarctic had been roughly the size of the United States.
In 1987, in response to the growing scientific consensus, 46 countries signed the Montreal Protocol on Substances that Deplete the Ozone Layer. This treaty is legally binding for phasing out the production and use of CFCs. It was later strengthened with a stricter and faster timeline. The production and import of new Freon was banned in the U.S. and other developed nations starting in 1996, and the developing countries were given time till 2010. China officially stopped the production of CFCs in July 2007 and ended consumption in January 2008, 2.5 years ahead of the schedule.
The 2025 Antarctic ozone hole was the fifth smallest since 1992. Since peaking around 2000, levels of ozone-depleting chlorine in the Antarctic stratosphere have dropped by about a third. The ozone layer is on track to recover to pre-1980s levels by around 2050. Full recovery of the ozone hole over Antarctica is projected for the late 2060s.
250 years of people, innovation, and leadership. That’s worth remembering. Happy Birthday, America.