Introduction
————
Profiling repetitive behavior in programs has historically been difficult. “Active profiling” identifies program phases by controlling the input of the program, and monitoring the occurrences of basic blocks in execution.
There are two important definitions:
(1) Phase: “A unit of predictable behavior in that its instances, each of which is a continuous segment of program execution, are similar in some important respect.”
(2) Phase Marker: A basic block that, when executed, is always followed by an instance of the program phase it marks.
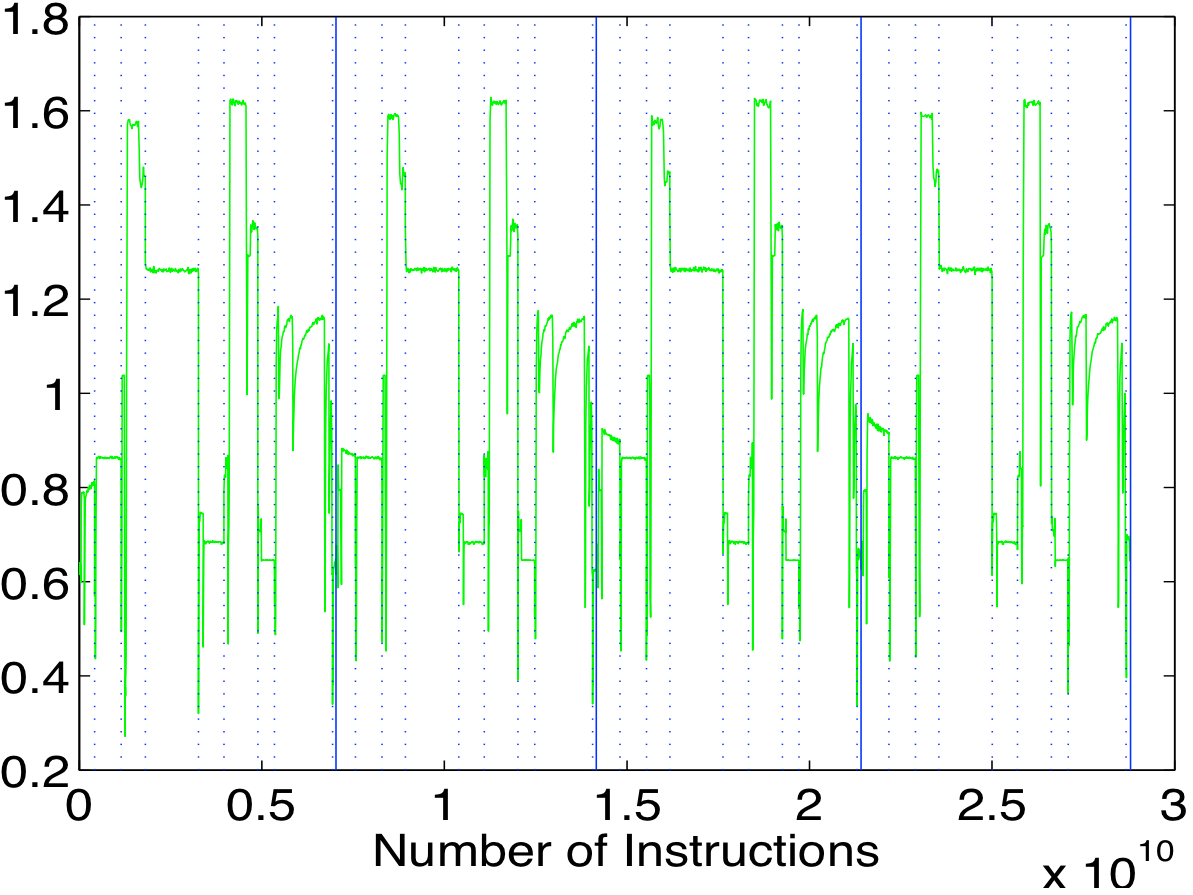
The above figure (Figure 2 in the paper) shows the IPC over logical time for GCC compiling a series of identical loops.
Selecting Phase Markers
———————–
The paper presents a 3-step method for identifying phase markers:
(1) The program is given a test input with f identical requests (e.g. in the figure compiling the same loop f times). Basic blocks which execute exactly f times are then selected as potential phase markers. Candidate phase markers whose inter-occurrence distances vary significantly are removed from consideration (because actual phase markers should occur at regular intervals).
(2) Analysis tests whether each remaining candidate occurs g times with other inputs that have g non-identical requests. If not, the candidate is removed from consideration.
(3) In step 3, inner-phases and their phase markers are identified.
Evaluation
———-
They test their system on 3 different programs with repetitive inputs, and show figures with phase markers for each:
(1) GCC: 4 identical functions.
(2) Compress: “A file that is 1% of the size of the reference input in the benchmark suite”. Compress has inherent repetition, because it compresses and decompresses the same input 25 times.
(3) L1: 6 Identical Expressions.
(4) Parser: 6 copies of a difficult-to-parse sentence.
(5) Vortex: A database and 3 iterations of lookups.
Uses of Behavior Phases
———————–
Garbage Collection: A behavior phase “often represents a memory usage cycle, in which temporary data are allocated in early parts of a phase and are dead by the end of the phase”. If garbage collection is run at the end of the phase, there is likely to be a higher fraction of garbage. Shen et al. implemented “preventive” garbage collection and applied it to the Lisp interpreter L1. (The standard “reactive” type of GC collects when the heap is full). Their testing results showed that preventive GC can result in faster execution times than reactive GC. However, in the test they showed, not using GC was faster than either of the GC options, so I’m not sure what to make of their result.
Memory Leak Detection: “If a site allocates only phase-local objects during profiling, and if not all its objects are freed at the end a phase, it is likely that the remaining objects are memory leaks.” This observation can be used to give programmers recourse to find memory leaks. Additionally, phase-local objects that are not freed by the end of the phase can be placed on the same virtual memory page. If not used, they will just go to disk, and not clog up memory.