This paper proposed a support for exploiting fine-grained data parallelism (SSE, AVX and GPU) for a set of applications which traverse multiple, irregular data structures (tree, NFA). There are two components in this support: 1. code generation: generating code that exploits the platform’s support on fine-grained data parallelism in a portable manner. 2. locality optimization: optimize the memory layout to improve inter-thread and intra-thread locality.
The paper is well organized. It first introduced the class of applications (irregular applications with independent traversal) the proposed method targets and challenges in optimizing them (unbalanced workload, divergence, pointer-based traversal). It then specifies the platforms it targets on: x86 system with SSE instructions and NVIDIA GPUs. (SIMD platform). The introduction ends with a list of contributions.
First, code generation and execution. The author developed an immediate language to describe the traversal of the target applications. This immediate language is used to enable portability of the algorithm. A runtime scheduler is responsible to execute the bytecode and perform some necessary dynamic optimization. One specific optimization mentioned in the paper is stream compaction. Stream compaction basically compacts the valid output of a vectorized operation together by “bubbling” the invalid output. This technique, as claimed by the author, can be extended to the GPU platform, with modifications.

Second, optimized data layout. The data layout of irregular data structure is to linearize the data elements in memory. There are two goals here, as clearly specified by the author: 1. co-locating nodes (in the same cache line) that are likely to be accessed concurrently by different threads (inter-thread locality). 2. co-locating threads that are accessed in successive steps by the same thread (intra-thread locality).
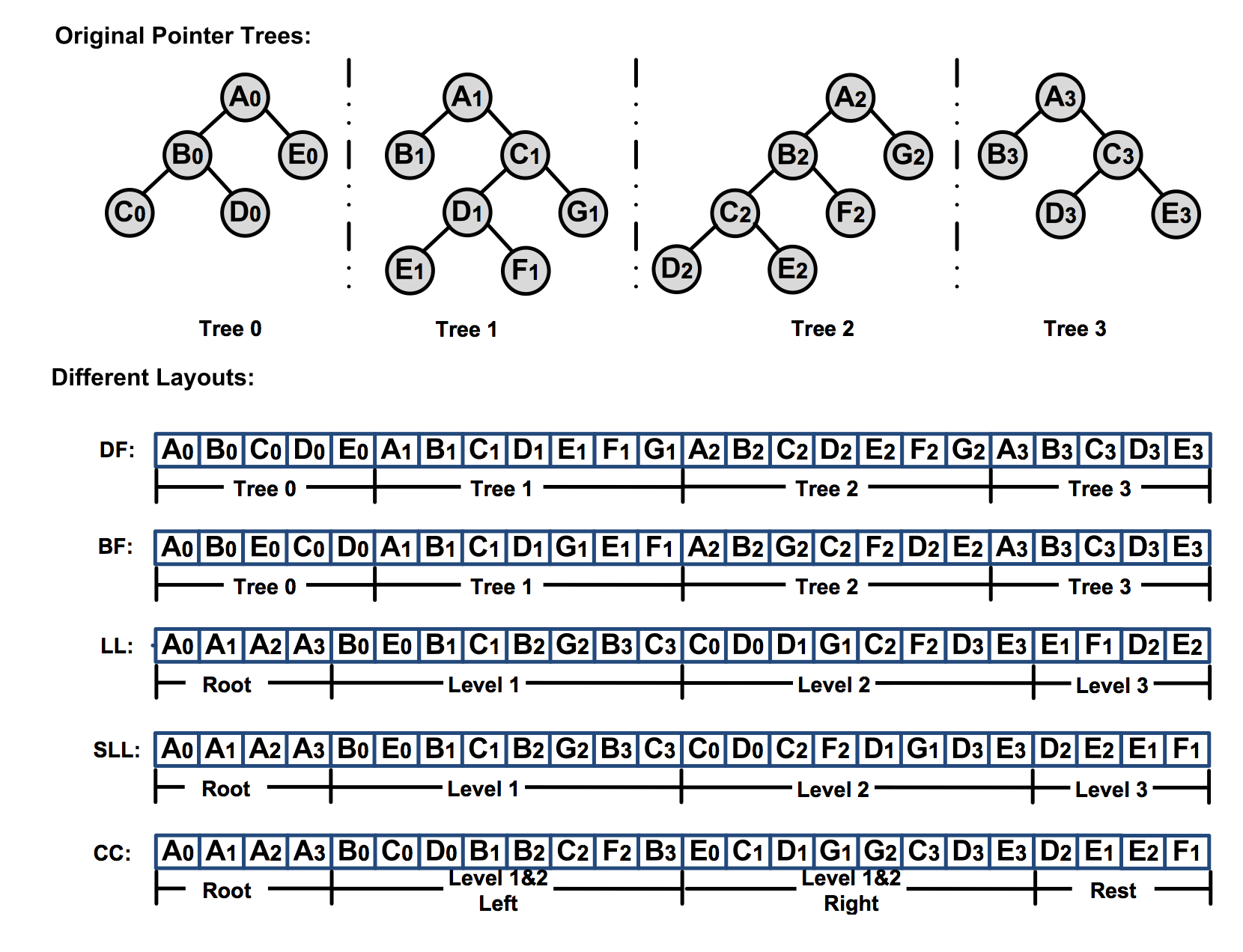
Take the traversal of 4 trees as example. There are 5 primitive layouts proposed in the paper. DF and BF correspond to Depth-First and Breath-First, which layout one single tree’s nodes together in memory. LL means level-by-level. It layouts the nodes at the same level (across multiple trees) together in memory. It has better locality for vectorized operations than the first two strategies. SLL is Sorted level-by-level. The author observed that in some cases, during the left children are biased over the right children. Therefore it is beneficial to group the nodes which are left children of their parents together. CC is Cache-Concious. It has an idea that when a parent is traversed, its children may immediately be accessed. Therefore it is beneficial to group parent nodes with child nodes while still maintaining level-by-level layout. These five layouts can be combined to form a hybrid layout, which is, the top x levels use SLL while the rest levels use CC. The value of x is a user-defined parameter, called switching parameter.
The author then analytically described a formula to calculate x for LL-CC hybrid layout and SLL-CC hybrid layout. The model is to minimized cache misses and thus *execution time*. There are assumptions in this model. First, no temporal locality considered, which means one node is traversed exactly once. Second, a complete binary tree. Also, to test whether a certain bias on left/right child exists, sampling is used.
To shortly summarize their evaluation, they observed up to a 12X speedup on one SIMD architecture. They also get as much as 45% speedup over a suboptimal solution.

The IR represents tree traversal operations such as moving left/right. SIMD instructions can be used to reshuffle and move all zeros to one end of a vector. A compiler can help to automatically generating code for different architectures, rather than programming SIMD assembly by a programmer. 5 different tree layouts were formalized. An automatic library would be very useful to let a user try different layouts without too much work.
As a followup, I just found that the authors have a followup work to be published in this year’s PLDI, “Efficient Execution of Recursive Programs on Commodity Vector Hardware”. It should be interesting to see the improvement.
I believe the cache-oblivious tree layout that I discussed here is a more profitable approach for layout optimization. https://roclocality.org/2015/02/18/algorithms-for-memory-hierarchy-meyer-sansers-sibeyn-the-external-memory-model-and-the-cache-oblivious-model/