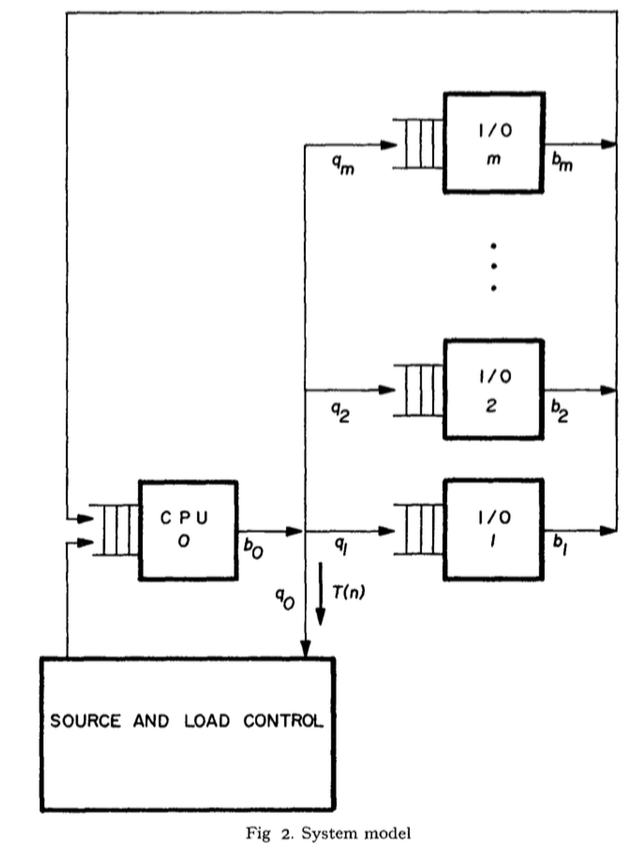
[FAST15]Carl A. Waldspurger, Nohhyun Park, Alexander Garthwaite, and Irfan Ahmad, CloudPhysics, Inc.
This paper proposed a sampling based miss ratio curve construction approach. It focus on reducing memory complexity of other algorithms from linear to constant.
Evaluation on commercial disk IO traces show it has a high accuracy with a low overhead.
Motivation
Algorithms for exact miss ratio curve usually consume a huge amount of memory, which is linear to unique reference(counted as M). Thus when M becomes dramatically huge, the memory overhead becomes a big problem. In this paper, authors analyzed VMware virtual disk IO data which is collected from commercial cloud, the size of disks are from 8GB to 34TB, with a median of 90GB. This size reflects range of M.
Thus authors propose a two phases spatial sampling algorithm to reduce space complexity, including sampling on address and an algorithm to restrict size of sampling.
Algorithm and Implementation
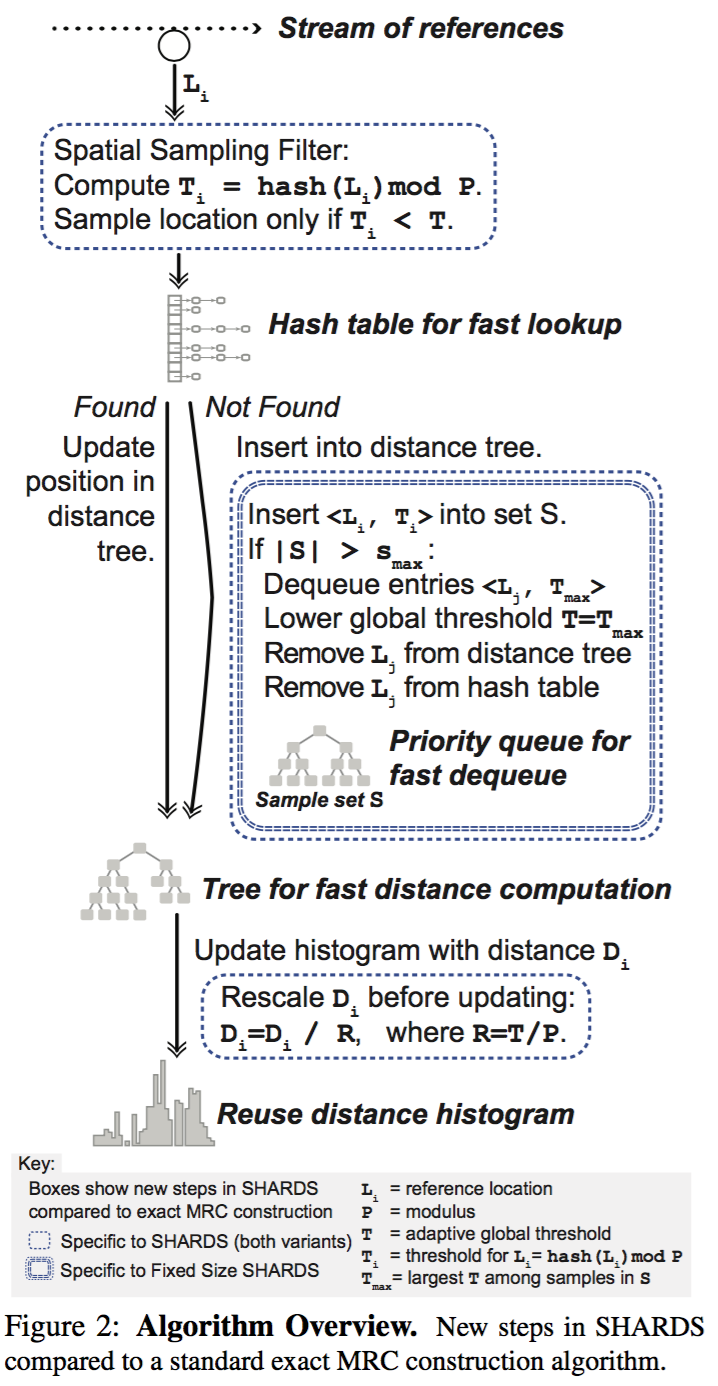
The algorithm contains 3 steps:
- sampling on addresses
- maintain fixed number of sampled addresses
- figure out reuse distance histogram while sampling
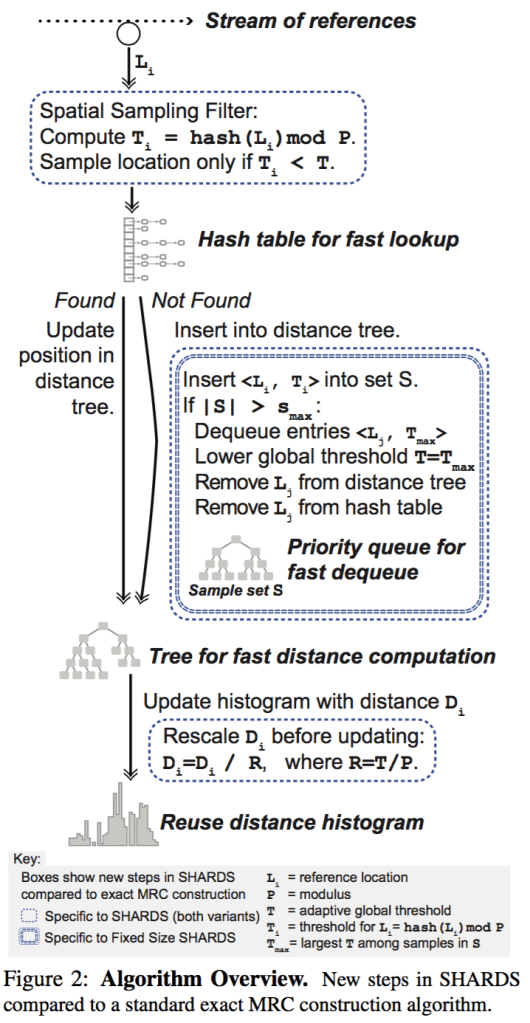
Sampling on address
For each address L, if hash(L) mod P < T, then this address is sampled. Thus sampling rate R = T/P.
Fixed number of address
Space complexity becomes M*R, and the objective is maximize R while M*R is less than specific boundary. But it is difficult to predicate M at runtime, thus it might not be a good decision to fix R at beginning of execution. Which means, it is necessary to adjust R at runtime, aka, decreasing R.
The approach is keeping a set S, which keeps all sampled values and their hash values, say for each address L[i], remember (L[i],T[i]). If |S| > S_max, then keep removing the one whom has maximal T[i] until |S| equal to S_max, and always let sampling boundary T = max(T[i]), where L[i] belong to S.
Reuse distance histogram
Reuse distance is computed with traditional approach, such as splay tree.
Since addresses space is sampled with rate R, thus the reuse distance is also scaled by R. For example, if distance d is gained through sampling, then before accumulating the histogram, d should be scaled to d/R.
Furthermore, since T will be adjusted according to previous section, and R = T/P, which means R will be adjusted at runtime, thus each time R is changed, the histogram should be rescaling again. In detail, all distance of the histogram should be multiplied by R_new/R_old.
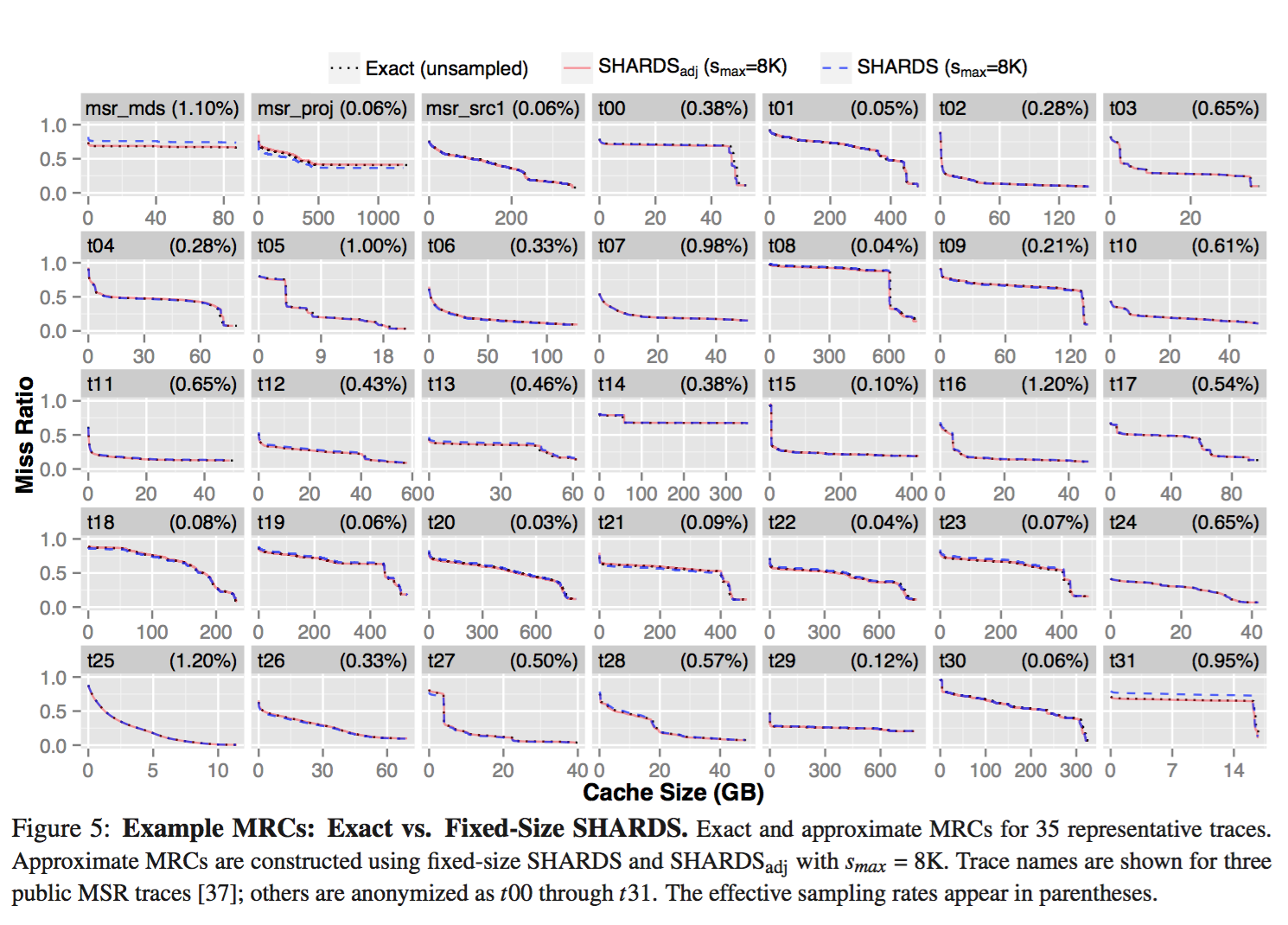
Evaluation
Data is collected by SaaS caching analytics service which “is designed to collect block I/O traces for VMware virtual disks in customer data centers running the VMware ESXi hypervisor”. “A user-mode application, deployed on each ESXi host, coordinates with the standard VMware vscsiStats utility [1] to collect complete block I/O traces for VM virtual disks.” In addition, the data is composed of 16KB sized block, and cached with LRU algorithm.
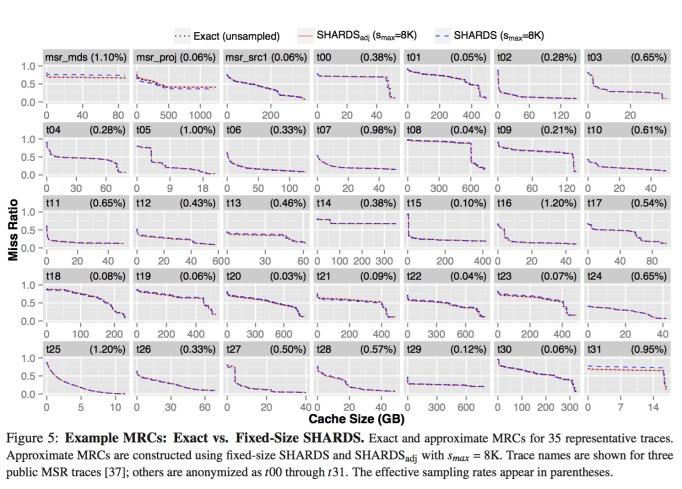
Appendix
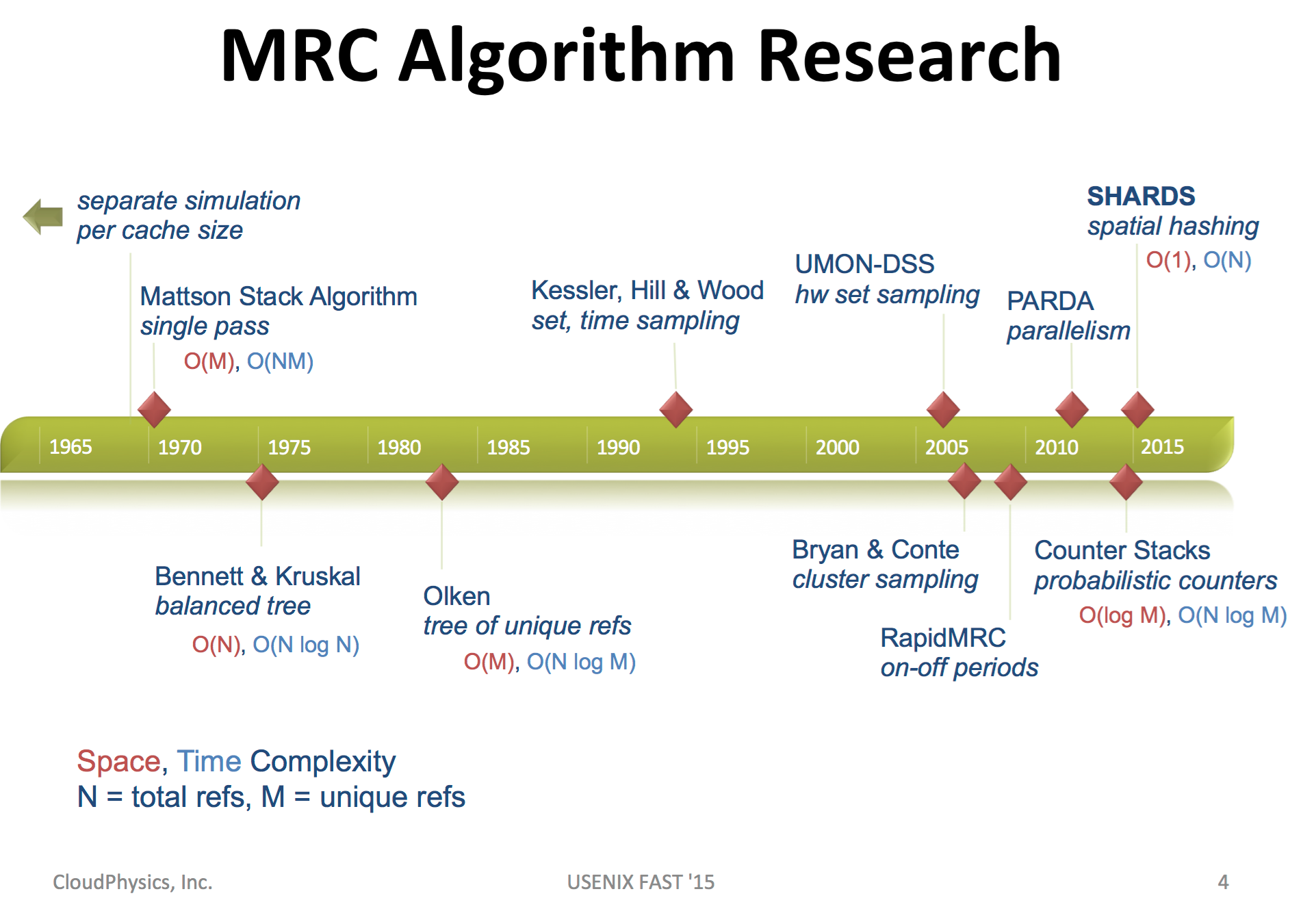
A great timeline comes from slides

Comes from Waldspurger etc. ‘s slides
How about temporal sampling
“Use of sampling periods allows for accurate measure- ments of reuse distances within a sample period. How- ever, Zhong and Chang [71] and Schuff et al. [45, 44] ob- serve that naively sampling every Nth reference as Berg et al. do or using simple sampling phases causes a bias against the tracking of longer reuse distances. Both ef- forts address this bias by sampling references during a sampling period and then following their next accesses across subsequent sampling and non-sampling phases.”