Yesterday, on my way to the YMCA for my 1700-meter swim, AC on high in 100-degree (“heat dome” over 163 million people across central and eastern US), I was chatting about the story of Freon—invention, then ban.
Freon was invented for air conditioning in 1930 in Dayton, Ohio. The goal was to find a safe, non-toxic replacement for the dangerous refrigerants of the time, such as ammonia and sulfur dioxide. The compound was later known as Freon-12 or CFC-12. It quickly led to the widespread adoption of safe and efficient air conditioning, in vehicles and homes and businesses across the country and then the world.
In 1972, U.S. chemist Rowland at a conference heard the detection of CFC-11 in the air over the Atlantic. This sparked his curiosity: if these human-made chemicals were accumulating in the atmosphere, what ultimately happened to them? Working with his post-doc Molina, they knew CFCs, including Freon, were designed to be inert and non-soluble, meaning they wouldn’t break down in the lower atmosphere through rain or common chemical reactions. The only fate was to drift slowly up to the stratosphere, where intense ultraviolet light would break them apart, releasing highly reactive chlorine atoms. Their model showed a single chlorine atom could act as a catalyst, destroying tens of thousands of ozone molecules in a chain reaction.
The journal Nature published their paper on June 28, 1974. In September, they held a press conference to share their results, initiating advocacy for policy change. Over the next few years, their theory was confirmed by U.S. scientists, institutions and equipment. In 1975, National Oceanic and Atmospheric Administration (NOAA) used air samples collected by weather balloons at heights up to 17.4 miles and found that CFCs were reaching the stratosphere in the predicted amounts and were being broken down at the expected altitudes. NASA Jet Propulsion Laboratory used high-altitude U-2 spy planes and weather balloons to measure hydrochloric acid in the stratosphere and found higher concentrations at higher altitudes (a source of chlorine), which aligned perfectly with the Molina-Rowland theory.
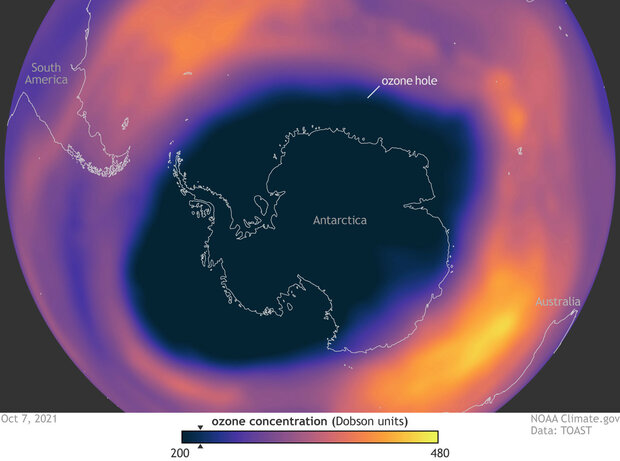
In October 1978, NASA launched Nimbus-7 satellite to carry equipment specifically designed to measure ozone: the Total Ozone Mapping Spectrometer (TOMS). It was groundbreaking because it could create daily global maps of total ozone, giving a bird’s-eye view of the ozone layer worldwide. When the British Antarctic Survey published in 1985 showing unexpectedly low ozone over Antarctica, the Nimbus-7 data became an essential independent check. In fact, TOMS recorded extremely low ozone values in 1983 and 1984, but the values were so far outside the expected range that the computer system flagged them as errors and filtered them out as “bad data.” After the British discovery was published, NASA scientists reviewed the archived TOMS data, reprocessed it without the erroneous low-value filter, and confirmed the findings. The satellite data showed that the dramatic thinning of the ozone layer over the Antarctic had been roughly the size of the United States.
In 1987, in response to the growing scientific consensus, 46 countries signed the Montreal Protocol on Substances that Deplete the Ozone Layer. This treaty is legally binding for phasing out the production and use of CFCs. It was later strengthened with a stricter and faster timeline. The production and import of new Freon was banned in the U.S. and other developed nations starting in 1996, and the developing countries were given time till 2010. China officially stopped the production of CFCs in July 2007 and ended consumption in January 2008, 2.5 years ahead of the schedule.
The 2025 Antarctic ozone hole was the fifth smallest since 1992. Since peaking around 2000, levels of ozone-depleting chlorine in the Antarctic stratosphere have dropped by about a third. The ozone layer is on track to recover to pre-1980s levels by around 2050. Full recovery of the ozone hole over Antarctica is projected for the late 2060s.
250 years of people, innovation, and leadership. That’s worth remembering. Happy Birthday, America.
This week, billions of people, 1.4 in mainland China, are enjoying their longest holiday of the year. It is a tradition time to reflect, mark an entry in this juncture in time, and share with others. With that spirit, here are my thoughts on the fifth day of the Year of Horse.
A recurring theme in traditional Chinese drama is the contrast between those who help others in urgent need and those who only add to the wealth of the rich. This sentiment appears in the book Slapping the Table in Astonishment (Part One), published around 1627—roughly 200 years after Zheng He’s ocean voyages. The original text reads:
This translates to: “In this world, few help those in desperate need, while many add to the fortunes of the already wealthy. Thus, the wise observe: ‘There are always those who gild the lily, but who brings charcoal in the snow?’ These words capture the true nature of human relationships.”
The idea of helping others—going out on a snowy night to deliver firewood to those without heat—once defined my understanding of charity. Before coming to Rochester, I believed that was exactly what charity meant: helping others. Living in Rochester, however, my perspective has changed.
Rochester has a rich legacy. In 1960s and 70s, the “Nifty Fifty” stocks are a group of high-growth, large-cap stocks popular with institutional investors and widely regarded as “one-decision”, that is, buy and never sell. Three of these are in Rochester: Kodak, Xerox, and Bausch & Lomb. George Eastman, who founded Kodak, had a wealth of $100 million (2 billion today) and gave most of it away: $50 million to University of Rochester including Eastman music school and $20 million to MIT (anonymously as Mr. Smith). In his late years, he suffered from a health condition which was extremely painful. After touring the new River Campus of University of Rochester, accompanied by then university president Rush Rhees, he returned home and committed suicide, leaving a brief note: “To my friends: my work is done. Why wait? G.E.”
Rochester is cited as the birthplace of the modern United Way movement. “Checking a box” on a payroll deduction form to donate and support the community is a direct descendant of this tradition. If just visiting, one would not see a difference, but living here for decades, I know how unusual for a city to have a deeply ingrained culture of giving back. Since around 2010, a few years after our second child was born, my family has been donating the equivalent of one dollar per person per day to United Way. In 2025, approximately 50,000 people donated about $16.7 million to this organization alone. The funds are used to support programs run by local charitable organizations. Many people, including us, also donate directly to these groups. I know people who volunteer in these programs. For example, one of our children’s music teacher and her husband volunteer one day each week doing cleaning work at Ronald McDonald House. The picturesque house sits by the canal and a short distance from the UR Hospital, with 24 private bedrooms to house terminally ill children, at no cost to their families. I feel fortunate to be able to donate to United Way and support volunteers who help others. But this is still not the whole meaning of charity.
Today I saw a passage by Vincent van Gogh, who wrote in 1882 to his brother Theo Van Gogh (who supported him through his life and died only 6 months after Vincent died).
What am I in the eyes of most people — a nonentity, an eccentric, or an unpleasant person — somebody who has no position in society and will never have; in short, the lowest of the low. All right, then — even if that were absolutely true, then I should one day like to show by my work what such an eccentric, such a nobody, has in his heart. That is my ambition, based less on resentment than on love in spite of everything, based more on a feeling of serenity than on passion. Though I am often in the depths of misery, there is still calmness, pure harmony and music inside me. I see paintings or drawings in the poorest cottages, in the dirtiest corners. And my mind is driven towards these things with an irresistible momentum. I’m seeking. I’m driving. I’m in it with all my heart. What would life be if we had no courage to attempt anything. (based on translation used by @soulxsigh on TikTok)
Here is what charity truly means: It is not only about helping others—it is also about allowing ourselves to be inspired. Whether it is someone enduring a cold winter night without heat, someone donating their time to lift others up, or someone uncompromisingly charting their own life path, we draw inspiration from them. And we will not be the only ones who find new strength and meaning in their example. A life well lived is one filled with moments of inspiration. In this light, our charity is simply investing our wealth to live a better life—first and foremost for ourselves.
Below is van Gogh’s painting titled Landscape with a Carriage and a Train, with a horse in the center (Source: https://en.wikipedia.org/wiki/Landscape_with_a_Carriage_and_a_Train). Wishing everyone a happy time in the Year of the Horse. 马到成功 (Mǎ dào chéng gōng) — may you succeed in arriving.
Fun fact: In 2020, Rochester United Way received a record $35 million donations. The unusual total is due to the historic $20 million gift from MacKenzie Scott.
Professor Tang was my undergraduate thesis advisor three decades ago. He passed away on Tuesday. Below is the English translation of the main passages of the article on Thursday in China’s Guangming Daily, full text in Chinese at https://mp.weixin.qq.com/s/JzjPkV0MMUjhlfibbRLNyw
Professor Tang Shiwei was born in December 1939 in Ningbo, Zhejiang Province. He graduated from the Computational Mathematics program of the Department of Mathematics and Mechanics at Peking University in 1964 and remained at the university to teach after graduation. He was promoted to professor in August 1990 and retired in December 2004.
Professor Tang Shiwei was a founder of the database as an academic discipline in China. He long dedicated himself to teaching and research in databases and information systems. He served as Director of the Database Research Laboratory in the Department of Computer Science and Technology at Peking University, Director of the Peking University Computing Center, Director of the Information Science Center, Director of the National Key Laboratory of Visual and Auditory Information Processing, Vice Chair of the Database Professional Committee of the China Computer Federation, and Professional Advisor to the Beijing Municipal People’s Government, making significant contributions to the development of computer science research and education in China.
At Peking University, he spearheaded the development of China’s independently copyrighted database management system, COBASE and the domestic system software platform COSA, for which COBASE was a key component and received a national award in 1996.
Original text in Chinese by Jin Haotian (晋浩天), correspondent, Guangming Daily
I took the database class around 1993, taught by his colleague Professor Yang, Dongqing (杨东清) and then joined their research group for my undergraduate thesis. I remember Professor Tang mentioning to me that they were the first in China to learn the development of databases in the US including reading the source code of early database systems. As a student assistant, I was sent to visit the Bank of China and talk to to account operators. It was pretty much deaf-mute conversation — I knew the textbook but nothing about applications let alone banking, but at the time I thought I was there to tell them what to do. Later a senior graduate student went to redo the visit. I was given part of the consulting fee even though my contribution might have been negative. Professor Tang was most generous and encouraging to me. I am fortunate and proud to be a part of his legacy.
Professor Tang also directed the undergrad thesis of Yuanyuan Zhou, now a professor at UCSD.
Logic in Coq. Logical Connectives: Conjunction, Disjunction, Falsehood and Negation, Truth, Logical Equivalence, Logical Equivalence, Existential Quantification. Programming with Propositions. Applying Theorems to Arguments. Coq vs. Set Theory: Functional Extensionality, Propositions vs. Booleans, Classical vs. Constructive Logic.
Inductively Defined Propositions. Induction Principles for Propositions. Induction Over an Inductively Defined Set and an Inductively Defined Proposition.
The Curry-Howard Correspondence. Natural Deduction. Typed Lambda Calculus. Proof Scripts. Quantifiers, Implications, Functions. Logical Connectives as Inductive Types.
This is a course required for the Bachelor of Science degree in Computer Science at the University of Rochester. A graduate must understand in depth the underlying physical reality which the virtual world including AI is built and depends on, i.e. the fundamentals of modern computer organization, including software and hardware interfaces, assembly language and C programming, memory hierarchy and program optimization, parallelism and operating systems. The textbooks are listed here.
There are two aspects for such a course in an elite research department like mine. First, the teaching focuses on fundamentals and goes in depth, which sets a high standard but this requirement is necessary for students to learn advanced subject courses later. Second, the material is updated often and part of it even experimental. In prior semesters, my colleagues Prof. John Criswell has emphasized on assembly and operating systems, Prof. Yuhao Zhu on gates and circuits, and Prof. Sree Pai on automatic (bit operation) correctness checking. My main change is the ISA.
RISC-V Instead of x86
Instruction Set Architecture (ISA) is essential in a BS CS degree and must be learned in this course which may be most hated material by a good number of students especially who have no prior knowledge of computer hardware. In my ancient PKU years, I learned Zilog Z80 (a microcontroller) and taught MIPS (classic RISC) and x86 (Intel/AMD) last time in this course in 2012. For the 2024 course, I evaluated Arm (Apple silicons) and the newest RISC-V. RISC-V is “open-source hardware” which means free for anyone to use. The course has the room to teach just one ISA; otherwise students will rebel.
I had a year to prepare for the course and tested this idea first before deciding on this significant change — This year’s students were the first (in Rochester) to learn RISC-V.
My NSF project with RIT has synthesized a RISC-V processor (papers here and here). I consulted my RIT collaborators who told me “x86 is too complex”, Arm is better but has “a lot of corner cases”, and for RISC-V, “I like it enough.” I learned about RISC-V over the years from computer architects to know the ISA is a good design, e.g., the first time in ASPLOS PC in 2019, but the RIT feedback made me think that the ISA is practical and learnable. The next question is whether it is teachable in a required undergrad class.
I purchased five or six single-board computers in both Arm and RISC-V and have them installed. Department staff Ian Ward installed Linux on Lichee-Pi 4A which has a quad-core processor, a GPU, and 8GB RAM for $130. The Arm processor (Raspberry Pi 4A) is weaker and does not run Linux.
My graduate TA Yifan Zhu (SchrodingerZhu on GitHub) installed the complete tool chain to compile and run RISC-V programs (in QEMU) on undergrad server (Intel) machines.
I found the 2024 textbook on RISC-V as recommended by the RISC-V foundation. The book reads well and covers the core knowledge: data representation, binary file and assembly, registers, data movement and control flow, application binary interface (ABI), all in 100 pages.
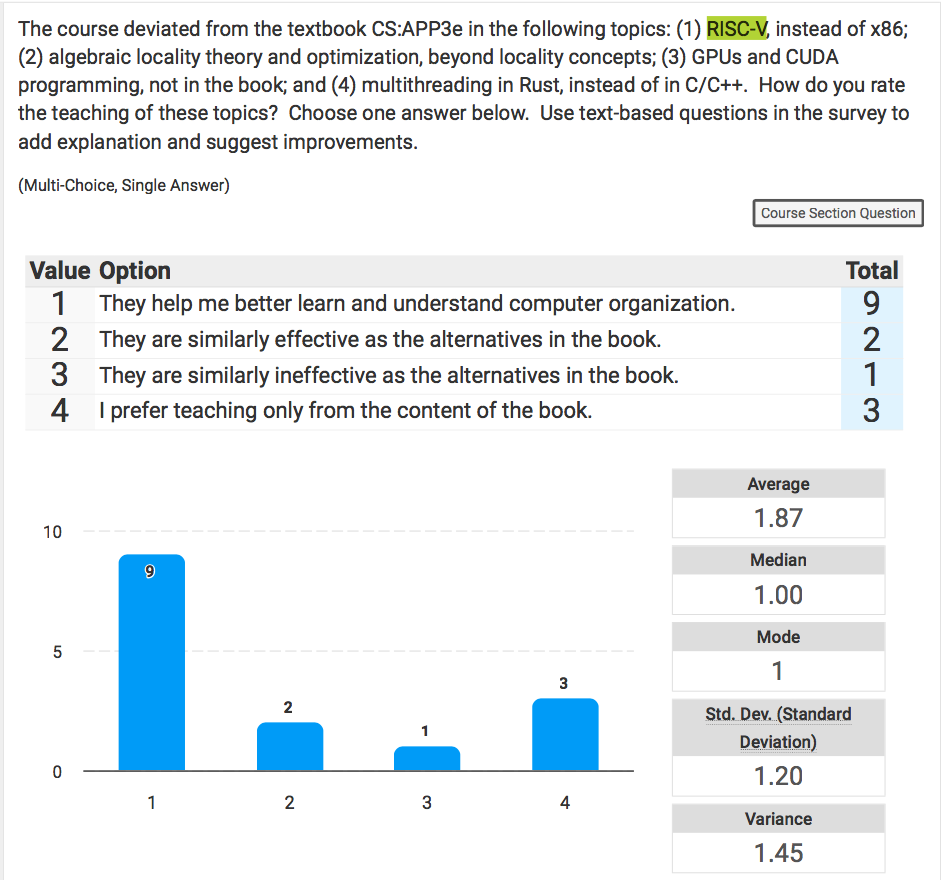
Here is the result. I summerized four changes in the following question (I created) in the Course Evaluation. Here are the question and the 15 responses:
RISC-V is newer and better designed, first with a core and then a series of extensions. The book covers RV32I, the core ISA. It is challenging to learn but learnable, unlike x86 which is too unwieldy, but it is 100 pages of material. Many students read the book and learned. They crossed a threshold of knowing the complete core, which they cannot do from learning x86.
Reading Books instead of Studying for Exams
At last semester’s CS Undergrad Town Hall where most CS faculty sat to listen to students’ feedback. One is that the department changes instructors of a course, and the exams are completely different from past years. I responded that a course teaches a subject, not a subject taught in a particular way and definitely not just exams. Exams are not the goal of learning or teaching, they are the feedback for both students and their teacher.
For this course, Prof. Zhu has made available past exams, problem sets, and their solutions (which I linked to in my course page). One can learn by studying these but shouldn’t use them as the primary source. Instead, students should learn by reading the textbooks. An important use of my lectures is to motivate students to read, show organization so they have mental map going in, and explain tricky/difficult examples and parts. When I find students don’t read textbooks, I use the lecture to read the book with them. My goal is for students to read the book and read it multiple times. The RISC-V book has the full content, updated, and readily accessible online.
The next and last 25 pages of the RISC-V book covers system-level programming (not covered in the course) but reading them (if/when they need to) would be a breeze once a student reads the first 100 pages.
In-person instead of Off-line Grading
The class has 64 students. 89 students registered, 21 dropped, and 5 withdrawn. Multiple students told me that they liked the course but felt not sufficiently prepared and will take the course next semester.
I myself cannot give every student the time and attention they deserve. There is no self deception/illusion/delusion here. I hired seven undergrad TAs. To maintain consistency, they must be primarily responsible for grading. The last thing I should do is to cherry pick and over rule their work.
There are two challenges to project grading. Computer organization is standard material, and the solutions of pass assignments and projects are abundant on the Web. One may say that students who choose to copy solutions waste their time and learning opportunity so who cares, but these are young minds that are often immature, so I do care to at least make it hard for them to fall. Using RISC-V reduces the severity of the problem.
The new problem is ChatGPT and other AI tools which could program in RISC-V. My TAs solved the problem with in-person grading. Students are divided into four groups and come to a TA session each week. They were required to explain their solution. In home work, students wrote and ran RISC-V programs using an emulator. At grading time, TAs set up an actual RISC-V machine so students saw their programs running native and for real.
In one project, the binary bomb, Yifan created the setup that students had practice bombs but when they came to grading, they were given a new bomb to defuse in 15 minutes.
The Result
The end test of a course is how well students have learned after a full semester. There were a total of 869 points across all assignments and exams. The final score is the ratio of student’s points over this total number. Here is the distribution:
50 students scored 80% and above, and all but 7 students were 70% or higher. I had the most fun problem which was deciding between a B+ and an A- for the 8 students who were between 88.94% and 90.2%. This is much better than what I expected from such a difficult course. I remember telling my colleagues who were duly impressed by my students. I am still immensely proud of what they have done.
Parting Thoughts
“One might as well say he has sold when no one has bought as to say he has taught when no one has learned.” — John Dewey in Logic The Theory of Inquiry
The course has its problems that can and should be improved. One that’s difficult to fix is that students learned RISC-V and then read the CS:APP textbook which uses x86. Right now, they have to map the book examples to RISC-V themselves. The evaluation score is 3.53 for overall instructor and 3.4 for the course, lower than my typical scores (here and here). Seven respondents gave the highest rating, and two the lowest. I appreciate students wrote in the evaluation and in public (here). What’s online is anecdotally true but not complete or comprehensive. My blog is partly to tell the part of the extensive learning that computer science students have accomplished in one of their courses in their four-year journey at Rochester.
Acknowledgements: including but not limited to CS staff Ian Ward and Dave Costello; my TAs Yifan, Boyang, Leo, Jacob, Kestor, Yekai, Zack, and Zachary; and my colleague John Criswell (for suggesting the xargs project).
This post is written for an assignment for CSC 252 based on my tutorial given at ACM Chapter workshop titled “General Introduction of Parallel Programming Schemes in Different Languages.”
Rust, like C or C++, is a system-level programming language, but unlike C and C++, it has more features on memory safety issues and useability. In other words, it “gives you the option to control low-level details (such as memory usage) without all the hassle traditionally associated with such control.”1
As mentioned above, Rust language is designed to focus on memory safety issues. To this end, Rust uses something called Ownership. “Ownership is Rust’s most unique feature and has deep implications for the rest of the language. It enables Rust to make memory safety guarantees without needing a garbage collector.”2 On the highest level, ownership means that some variable owns some value, and the can only be one owner for a value at a time. Specifically, the Rust Book defines the ownership rules as:
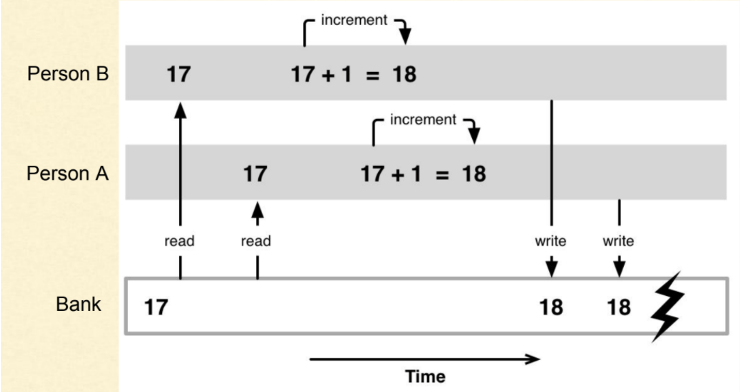
This ownership concept not only solves the memory safety issues but also makes writing concurrent programs much more accessible than expected. Having ownership makes issues such as data race compile-time errors rather than runtime errors in many cases.
Rayon in Rust
Like OpenMP and OpenCilk in C and C++, Rayon is a data-parallelism library in Rust that helps you write parallel code safely and quickly, which eases you from manual manipulation of threads.
There are two ways to use Rayon:
High-level parallel constructs are the simplest way to use Rayon and also typically the most efficient.
Parallel iterators make it easy to convert a sequential iterator to execute in parallel.
The ParallelIterator trait defines general methods for all parallel iterators.
This tutorial will only cover the most basic method of parallelizing matrix multiplication using Rayon, which is using parallel iterators (more can be found at: https://docs.rs/rayon/latest/rayon/).
The most naive way of matrix multiplication in Rust is shown below:
fn seq_mm(a: &[f64], b: &[f64], c: &mut [f64], n: usize) {
for i in 0..n {
for j in 0..n {
for k in 0..n {
c[i * n + j] += a[i * n + k] * b[k * n + j];
}
}
}
}
By using par_chunks_mut, we can divide the matrix c into n distinct, separate sections, with each section smaller than or equal to n. Rayon then automatically processes these sections in parallel for us.
fn par_mm(a: &[f64], b: &[f64], c: &mut [f64], n: usize) {
c.par_chunks_mut(n)
.enumerate()
.for_each(|(i, c_row)| {
for j in 0..n {
for k in 0..n {
c_row[j] += a[i * n + k] * b[k * n + j];
}
}
});
}
With n=1000 and no other optimizations (meaning cargo run), the sequence matrix multiplication takes around 7 seconds to finish, while the parallel matrix multiplication takes only around 2 seconds.
Conclusion
In conclusion, Rayon in Rust seems to be beginner-friendly and easy to use, producing a relatively good performance without much work. If you are interested in Rayon or Rust, be sure to check out the Rust Book.
In the Spring 2023 semester, a group of Parallel and Distributed Programming (CSC 248/448) students showcased their remarkable research and implementations in a series of presentations. Their projects span a wide range of fields, from optimization algorithms to parallel computing frameworks. Here is some brief Information about their presentations.
Aayush Poudel: Ant Colony Optimization (ACO) for the Traveling Salesman Problem (TSP)
Aayush Poudel’s presentation revolved around the fascinating application of Ant Colony Optimization to solve the Traveling Salesman Problem.
Matt Nappo: GPU Implementation of ACO for TSP In his presentation
By harnessing the parallel processing capabilities of GPUs, Matt demonstrated an efficient implementation of ACO for the Traveling Salesman Problem.
Yifan Zhu and Zeliang Zhang: Parallel ANN Framework in Rust
Yifan Zhu and Zeliang Zhang collaborated on a project that involved building a parallel Artificial Neural Network (ANN) framework using the Rust programming language. Their framework leveraged the inherent parallelism in neural networks, unlocking increased performance and scalability.
Jiakun Fan: Implementing Software Transactional Memory using Rust
Jiakun Fan delved into concurrency control by implementing Software Transactional Memory (STM) using the Rust programming language. STM provides an alternative approach to traditional lock-based synchronization, allowing for simplified concurrent programming. Jiakun’s project showcased the feasibility of utilizing Rust’s unique features to build concurrent systems.
Shaotong Sun and Jionghao Han: PLUSS Sampler Optimization
Shaotong Sun and Jionghao Han collaborated on a project to optimize the PLUSS sampler. Their work involved enhancing the performance and efficiency of the sampler through parallelization techniques.
Yiming Leng: Survey Study of Parallel A*
Yiming Leng undertook a comprehensive survey study exploring the parallelization of the A* search algorithm. A* is widely used in pathfinding and optimization problems, and Yiming’s research focused on the potential benefits and challenges of parallelizing this popular algorithm.
Ziqi Feng: Design and Evaluation of a Parallel SAT Solver
Ziqi Feng’s presentation concerned designing and evaluating a parallel SAT (Satisfiability) solver. SAT solvers play a crucial role in solving Boolean satisfiability problems, and Ziqi’s project aimed to enhance their performance by leveraging parallel computing techniques.
Suumil Roy: Parallel Video Compression using MPI
Suumil Roy’s project focused on leveraging the Message Passing Interface (MPI) for parallel video compression. Video compression is crucial in various domains, including streaming and storage. By leveraging the power of parallel computing, Suumil demonstrated how MPI enables the efficient distribution of computational tasks across multiple processing units.
Muhammad Qasim: A RAFT-based Key-Value Store Implementation
Muhammad Qasim’s presentation focused on implementing a distributed key-value store using the RAFT consensus algorithm. Key-value stores are fundamental data structures in distributed systems, and the RAFT consensus algorithm ensures fault tolerance and consistency among distributed nodes.
Donovan Zhong’s project complemented Muhammad’s work by presenting another RAFT-based key-value storage implementation perspective. Donovan’s implementation provided insights into the challenges and intricacies of building fault-tolerant and distributed key-value storage systems.
Luchuan Song: Highly Parallel Tensor Computation for Classical Simulation of Quantum Circuits Using GPUs
Luchuan Song’s presentation unveiled an approach to parallel tensor computation for the classical simulation of quantum circuits. Quantum computing has the potential to revolutionize various industries, but its simulation on classical computers remains a challenging task. Luchuan’s project harnessed the power of Graphics Processing Units (GPUs) to accelerate tensor operations, allowing for efficient and scalable simulation of quantum circuits.
Woody Wu and Will Nguyen: Parallel N-Body Simulation in Rust Programming Language
Working together as a team, Woody Wu and Will Nguyen tackled the intricate task of simulating N-body systems. N-body simulations involve modeling the interactions and movements of particles or celestial bodies, making them essential in various scientific domains. In collaboration, they presented their project using various parallel programming frameworks such as Rust Rayon, MPI, and OpenMP. By leveraging these powerful tools, they explored the realm of high-performance computing to achieve efficient and scalable simulations.
Leasing by Learning Access Modes and Architectures (LLAMA) Jonathan Waxman
November 2022
Lease caching and similar technologies yield high performance in both theoretical and practical caching spaces. This thesis proposes a method of lease caching in fixed-size caches that is robust against thrashing, implemented and evaluated in Rust.
Prerequisites: CSC 172 or equivalent for CSC 253. CSC 172 and CSC 252 or equivalent for CSC 453 and TCS 453.
Modern software is complex and more than a single person can fully comprehend. This course teaches collaborative programming which is multi-person construction of software where each person’s contribution is non-trivial and clearly defined and documented. The material to study includes design principles, safe and modular programming in modern programming languages including Rust, software teams and development processes, design patterns, and productivity tools. The assignments include collaborative programming and software design and development in teams. Students in CSC 453 and TCS 453 have additional reading and requirements.
Syllabus
SOFTWARE DESIGN
Essential Difficulties
Complexity, conformity, changeability, invisibility. Their definitions, causes, and examples. Social and societal impacts of computing.
Module Design Concepts
Thinking like a computer and its problems. Four criteria for a module. Modularization by flowcharts vs information hiding. The module structure of a complex system. Module specification.
Software Design Principles
Multi-version software design, i.e. program families. Stepwise refinement vs. module specification. Design for prototyping and extension. USE relation.
Software Engineering Practice
Unified software development process, and its five workflows and four phases. CMM Maturity.
Teamwork
Types of teams: democratic, chief programmer, hybrids. Independence, diversity, and principles of liberty. Ethics and code of conducts.
PROGRAM DESIGN USING RUST
Safe Programming
Variant types and pattern matching. Slices. Mutability. Ownership, borrow, and lifetime annotations. Smart pointers.
PPoPP Workshop on Principles of Memory Hierarchy Optimization (PMHO)
Sunday 2/28/2021 9am to 1pm US EST (China 10pm to 2am, Europe 3pm to 7pm, US PST 6am to 10pm, US MST 7 am to 11 am)
Opening and Logistics (9am)
Session 1: Algorithm Locality (9:10am to 9:50am)
Data Movement Distance: An Asymptotic and Algorithmic Measure of Memory Cost, Chen Ding, with Donovan Snyder, University of Rochester, unpublished (video)
KEYNOTE: Working Sets, Locality, and System Performance, Peter Denning, Naval Post Graduate School, ACM Computing Surveys 2021 (video)
Session 2: Optimality (10:30am to 11:30am)
Some mathematical facts about optimal cache replacement, Pierre Michaud, Inria, ACM TACO 2016 (video)
Practical Bounds on Optimal Caching with Variable Object Sizes, Nathan Beckmann, Cargenie Mellon University, ACM SIGMetrics 2018 (video)
Category Theory in the Memory Hierarchy, Wesley Smith, University of Rochester, Unpublished (video)
Session 3: Applied Theories (11:40am to 1pm)
Optimal Data Placement for Heterogeneous Cache, Memory, and Storage Systems, Lei Zhang and Ymir Vigfusson, with Reza Karimi and Irfan Ahmad, Emory University, ACM SIGMetrics 2020 (video)
PHOEBE: Reuse-Aware Online Caching with Reinforcement Learning for Emergin Storage Models, Pengcheng Li, with Nan Wu, Alibaba, arxiv 2020 (video)
Data-Model Convergence and Runtime Support for Data Analytics and Graph Algorithms, Antonino Tumeo, Pacific Northwest National Laboratory, ACM Computing Frontiers 2019 (video)
Performance Prediction Toolkit for GPUs Cache Memories, Yehia Arafa and Hameed Badawy, New Mexico State University, ACM International Conference on Supercomputing (ICS) 2020 (video)
Call for Presentations
Data movement is now often the most significant constraint on speed, throughput, and power consumption for applications in a wide range of domains. Unfortunately, modern memory systems are almost always hierarchical, parallel, dynamically allocated and shared, making them hard to model and analyze. In addition, the complexity of these systems is rapidly increasing due to the advent of new technologies such as Intel Optane and high-bandwidth memory (HBM).
Conventional solutions to memory hierarchy optimization problems are often compartmentalized and heuristic-driven; in the modern era of complex memory systems these lack the rigor and robustness to be fully effective. Going forward, research on performance in the memory hierarchy must adapt, ideally creating theories of memory that aim at formal, rigorous performance and correctness models, as well as optimizations that are based on mathematics, ensure reproducible results, and have provable guarantees.
PMHO 2021 is a forum dedicated to the theoretical aspect of memory hierarchies as well as their programming models and optimization.
Format and Topics
PMHO 2021 will be a specialized and topic-driven workshop to present ongoing, under review, or previously published work related to the following non-exhaustive topic list:
Mathematical and theoretical models of memory hierarchies including CPU/GPU/accelerator caches, software caching systems, key-value stores, network caches and storage system caches
Algorithmic and formal aspects of cache management including virtual memory
Programming models and compiler optimization of hierarchical complex memory systems
There will be no formal peer review process or publication, and presentations will be a mix of selections from submissions and invited presentations.
The workshop will take place online Sunday February 28, 2021.
Submission
Submit your presentation proposal to save-g4jFdqmK9rqH@3.basecamp.com. Submissions should consist of an one-page abstract of the topic you intend to present alongside any (optional) pertinent publications or preprints.
The submission deadline is Friday January 22, 2021 AOE.