Uncategorized
Erratum in Timescale Functions for Parallel Memory Allocation [Li et. al., 2019]
Elias Neuman-Donihue, University of Rochester, May 2020
A small correction to Li et. al.’s paper: in section 3.2, the length of a time window is defined as “its end time minus its start time plus one.” However, in section 3.2.1, there is a reference to “windows of length k from 0 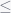
One such error is the calculation of reuse(1): by the stated definition, an interval of length k=1 has only one allocation, so the reuse should be one if the window also contains a matching free operation and 0 otherwise. Therefore, since there are a total of n windows of length 1, the average reuse of all such windows should be:


However, by the formulae stated in 3.2.2:
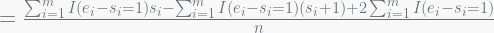
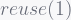
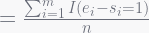


In order to standardize the equations with the provided definition of window length, a few changes must be made:
In Eq. 1 and Eq. 2, every instance of 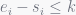

Then in Eq. 2,

The recursive equations should then read

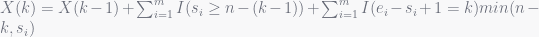

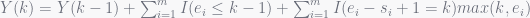


Good luck penny
(Sent to my class on the exam day)
NY Times collects and publishes New York city stories submitted by its readers at https://www.nytimes.com/column/metropolitan-diary. The May 3 entry was Christopher Fryer who remembered “joys of city life walking every day from our apartment on the Upper West Side through Central Park, and then down Sixth Avenue to my office at 46th Street”, found “a shining Lincoln head on the penultimate step”, “paused to pick it up, being careful not to impede either the people coming up behind me or those who were heading down into the station”, and “a man on his way down the stairs spoke without breaking stride.
“Hey,” he said. “ I saw one of those at 125th Street. If you hurry you can probably get that one, too.”
With that piece, other readers made comments, including this one by Susan Hayes from NJ:
Re finding pennies and other coins, I was always told that they had to be face up to be “good luck.” I read somewhere a long time ago about a kind soul who would turn coins over when found face down so the next person to see them would have good luck, so I do that. It’s a little like being Santa Claus.
This is yet another proof of the CSC 200H theme: even good luck requires collaboration.
Chen Ding Receives Lewis College Award
On Friday I received the Frederick D. and Susan Rice Lewis College Award for Undergraduate Teaching and Research Mentorship. It was delightful to see everyone including many of my current and former students. I prepared and delivered the following speech:
Thanks to Fred and Susan Lewis for creating this award and for being here, to Dean Runner, Mike, Cesar, and Chris for your generous words, to Department Chair Dr. Dwarkadas for the nomination, and Ms. Logory for organizing today’s event.
Thanks to the terrific computer science department, to our staff, especially the tireless work of Eileen Pullara. Countless times I have asked her: can I hire another undergrad. It is a community of support. I’m standing on the shoulder of not just the department, but also the university community and the scientific community.
Let me first state my teaching philosophy by quoting the Chinese philosopher Confucious from 2000 years ago, who he himself was a teacher. He said, and I translate: Achieve independence by making others independent. Achieve prosperity by making others prosperous.
As university faculty, we are Stewards of Knowledge. My colleague Randal Nelson once compared education and business, he said, I quote: “The fundamental currency of a university is knowledge; while that of a corporation is capital. Both traffic information, money, and talented human beings, … but the bottom-line metric differs. ” Money, resource and capital have limits. It is often called a zero sum game. Knowledge knows no limits.
In teaching, I specialize in programming languages and systems. I show students a cartoon. This is an interview room at Ikea. The text in black instructs the nervous interviewee: “make a chair and take a seat”, the text in red is for my class “invent a language and talk.”
Interesting problems are abound: How do we describe a language when we do not yet have a language? Similar circular problems in Cesar’s research then and Mike’s research now in memory allocation. Similarly in my Confucious motto: independence and prosperity are problems that cannot be solved in isolation.
In most courses I teach, students learn by doing. Alan Perlis, the first recipient of Turing award in 1966, said “You think you know when you can learn, are more sure when you can write, even more when you can teach, but certain when you can program.” To understand a programming language, you must not just learn it but to build it.
How do we create knowledge?
We discover it through science, first by measuring. We are in the dark and remain so until we measure. The Unite State’s response to the coronavirus is hampered by a president who communicates by tweets, by politicizing the response to the crisis, and most damaging by anti-science arrogance and idiocy.
The first step it missed and still missing is testing. Without testing there is no science, and there is no knowledge. This ignorance puts medical personnels and emergency responders and their family in danger and we begin to see disproportional fatalities in poor city neighborhoods, indigent population and people with disabilities.
This Wednesday I was most proud to see our University News photo: our medical school colleagues return from helping in NYC. In teaching, as in medicine, we work with knowledge and skill.
Like our medical colleagues, we work together. We collaborate.
The best teacher-student relation is symbiotic. I confess when I first taught computer organization, the evaluation wasn’t good. A common criticism, believe it or not, was that the professor gave too many extensions. The next year, I set a schedule and followed it. Then the department machines had to be shut down for days due to the cooling water system repair in the building. I held the line and told my students that we don’t need extensions for lack of cooling, not in the middle of the winter, not in Rochester. I received high scores for that course.
At a research university like ours, teaching keeps a close pace with technology.
This semester I am teaching new material of machine-checked proofs.
Knowledge is not just the truth but more importantly the proof. Proof is knowledge about knowledge — how do we know we know.
This is unprecedented material which combines the programming language and the language of logic. (1) Programming encodes reasoning, (2) reasoning verifies programming. (3) With computers, programming automates reasoning. (4) Even more exciting is the new way to collaborate — our reasoning can be combined as our programs can. (5) Most exciting is where our students will go taking the knowledge. Three undergrads and their TA are “programming” a proof for a joint paper with my colleagues and may introduce machine-checked proofs to the database community.
We teach technology. We collaborate to develop technology. We also teach and develop technology to amplify collaborative work.
University of Rochester, its size, not too big and not too small, and its combination of research and liberal arts education, make it a best place to collaborate.
The best collaboration is to inspire and be inspired. Let me take just one minute to give two examples.
Lane Hemaspaandra created the honor course I’m teaching now and he continues to help and model for me in teaching collaborative problem solving.
Chris Tice when he was a student solved an extra credit problem after the assignment was due. So why doing extra work for no credit. He said that he didn’t have time to work on it, but he was interested so he went back once he had time. When a student is not there just for the grade, a teacher is not here just for grading. It is what Hajim said at every commencement, if you love your work, you never have to work.
To summarize, I have started with my motto of independence and prosperity and highlighted three ingredients of a happy life: to collaborate, discover, and inspire. To help you remember, the initials CDI are the first three letters of my university NetId.
I want to thank people who inspired me the most: my longest time colleagues, mentors and supporters Michael Scott and Sandhya Dwarkadas, my graduate advisors late Dr. Ken Kennedy and Philip Sweany, my mother Ruizhe Liu who’s currently battling cancer, for her unyielding courage and support, my father Shengyao, my brother Rui, my dear wife and Rochester graduate Dr. Linlin Chen and our two children Yawen and Shuwen who were both born in Rochester.
Last, let me share a few road trip photos. In 2016, we went to conference in DC, we zoomed by at 90 miles an hour in Pennsylvania but then sit still in traffic the minute we got to Baltimore, but had fun counting the many Rs. Once arrived, undergrads had homework. The book on the table was Michael’s popular textbook, in its fourth edition. At the award banquet, we were the Rochester 9, the following year we had a smaller group and Google flew one of the undergrads out for interview, but in this photo we were the largest group and was so recognized.
I received an award for that exact reason — the award for being the largest group attending the conference. Inspired, I told my students: you see — 100% of success is just showing up.
Then it was literally true for that award. Today I feel the same for this award. It is most humbling. Thank you all.
Other than the people I thanked above, I am also grateful for the many who joined the meeting and for the spontaneous comments following the event by my colleagues Michael Scott and Sandhya Dwarkadas and my former doctoral graduates Xiaoming Gu, Chengliang (Cheng) Zhang, Pengcheng Li, and Xipeng Shen. Quoting Dr. Cheng Zhang who was attending from home in Seattle and said that through his work in Microsoft, Amazon and now Google, he collaborate in a team and he work to lift others.
It was most fun, heart warming, and well organized. There wasn’t even problems with the network.
Funding Sources
Acknowledgement. The on-going research is supported by the National Science Foundation (Contract No. SHF-2217395, CCF-2114319). The past support came from the National Science Foundation (Contract No. CNS-1909099, CCF-1717877, CCF-1629376, CNS-1319617, CCF-1116104, CCF-0963759, CNS-0834566, CNS-0720796, CNS-0509270, CCR-0238176, CCR-0219848 and EIA-0080124), IBM CAS Faculty Fellowships, the Department of Energy (Contract No. DE-FG02-02ER25525), the National Science Foundation of China (Contract No. 61328201), two grants from Microsoft Research, a grant from Huawei, and equipment support from Intel. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding organizations.
How to make our ideas clear
This text is sent to my advisees at the start of the spring 2019 semester.
In modern day with vast information at our fingertips and suggestions of content displaced every time we click or touch, it’s important to keep in mind that our mind can be overwhelmed and lose clarity. Yet the earliest lesson that students should demand a school to teach is, how to make our ideas clear.
For this, I here borrow the title of Charles Peirce’s 1878 article and some of his ideas about ideas, in his exact words.
“To know what we think, to be masters of our own meaning, will make a solid foundation for great and weighty thought. It is most easily learned by those whose ideas are meager and restricted; and far happier they than such a wallow helplessly in a rich mud of conceptions.”
“A few clear ideas are worth more than many confused ones. A young [person] would hardly be persuaded to sacrifice the greater part of [one’s] thoughts to save the rest; and the muddled head is the least apt to see the necessity of such a sacrifice. [It is] a person with a congenital defect. Time will help, but intellectual maturity with regard to clearness comes rather late, an unfortunate arrangement of Nature, inasmuch as clearness is of less use to a [person] settled in life … than it would be to one whose path lies [in front].”
“It is terrible to see how a single unclear idea, a single formula without meaning, lurking in a young man’s head, will sometimes act like an obstruction of inert matter in an artery, hindering the nutrition of the brain, and condemning its victim to pine away in the fullness of his intellectual vigor and in the midst of intellectual plenty.”
“Many a man has cherished for years as his hobby some vague shadow of an idea, too meaningless to be positively false; he has, nevertheless, passionately loved it, has made it his companion by day and by night, and has given to it his strength and his life, leaving all other occupations for its sake, and in short has lived with it and for it, until it has become, as it were, flesh of his flesh and bone of his bone; and then he has waked up some bright morning to find it gone, clean vanished away … and the essence of his life gone with it.”
Full text of the article is at http://www.peirce.org/writings/p119.html
Protected: Trace Analysis and a New Working Set Metric
CSC 253/453 Fall 2018
CSC 253/453 Fall 2018
Dynamic Language & Software Development
Prerequisites: CSC 252 and CSC 254 are required for CSC 453 and recommended for CSC 253. Familiarity with a dynamic programming language such as Python is required for CSC 253.
Crosslisted: TCS 453 (same requirement as CSC 253)
This course studies dynamically-typed programming languages and modular software development. Topics include principles and practice of modular design, functional and object-oriented programming techniques, software engineering concepts, software correctness and reliability, programming tools, and design examples. Ruby is used as the main instruction language. The lessons complement those in traditional compilers and programming languages courses, which focus mainly on statically-typed languages and individual algorithms rather than system design. A significant portion of the assignment is a group project.
Teaching Staff and office hours: Prof. Chen Ding, Fridays 11am to 12pm in Wegmans Hall 3407, x51373. Yu Feng, 5pm to 6pm, Mondays and Wednesdays, Wegmans Hall 3407. Patrick Ferner, 2:30pm to 3:30pm, Tuesdays, Wegmans 2215 (updated 9/11).
Policies for grading, attendance, and academic honesty (updated 8/27)
Grading:
- mid-term and final exams, 15% each
- two written homeworks, 5% each
- assignments and projects, 60%
Assignments are typically handed out on Wednesday and due the following Tuesday midnight.
Preparation (before first class):
“No Silver Bullet — Essence and Accidents of Software Engineering” is a classic paper on software engineering written by Turing Award winner Fred Brooks in 1986. Read the paper (available here if accessed inside the UR network) pages 3 to 5 on the “essential difficulties” of software development and skim the rest of the paper.
“A former member of the SD10 Panel on Computing in Support of Battle Management explains why he believes the ‘star wars’ effort will not achieve its stated goals.” Read the paper (available here if accessed inside the UR network) pages 2 to 4 the section titled “Why software is unreliable.” Which of the “essential difficulties” was Parnas discussing?
More background of this debate, detailed rationales and an illuminating discussion of the ethical issues can be found in another article of Parnas: “SDI: A Violation of Professional Responsibility”. The article does not seem to have a free version online, but you can read it by borrowing the book “Software Fundamentals” (included as Chapter 27) from the textbook reserve for CSC 253/453 at the Carlson Library. The lease is two hours.
Further material will be distributed through the Blackboard web site for students who have registered. Contact the instructor if you have problem accessing the site.
Textbooks (online access at learn.rochester.edu > CSC 253 > Reserves > Materials on Reserve in the Library):
| Software fundamentals : collected papers by David L. Parnas Author: Parnas, David Lorge. Imprint: Boston : Addison-Wesley, 2001. On Reserve at: Carlson Library Reserve Desk 2nd Floor Call Number: QA76.754 .P365 2001 |
Object-oriented Software Engineering
Author: Schach, Stephen R.
Imprint: New York : McGraw-Hill, c2008.
Available at school book store. On Reserve at: Carlson Library Reserve Desk 2nd Floor
| Design patterns in Ruby [electronic resource] Author: Olsen, Russ. Imprint: Upper Saddle River, NJ : Addison-Wesley, c2008. Available through Carlson Library at: Internet |
Programming Languages: Application and Interpretation (http://cs.brown.edu/~sk/Publications/Books/ProgLangs/2007-04-26/)
Copyright © 2003-07, Shriram Krishnamurthi
(Also see Prof. Findler’s course EECS 321 at https://www.eecs.northwestern.edu/~robby/courses/)
Learn You a Haskell for Great Good!
A Beginner’s Guide
by Miran Lipovača (http://learnyouahaskell.com)
No Starch Press, April 2011.
Programming Language Pragmatics, 4th Edition
Author: Scott, Michael L.
On Reserve at: Carlson Library Reserve Desk 2nd Floor
Call Number: CRL PersCpy
Other Materials
| Ruby under a microscope [electronic resource] : an illustrated guide to Ruby internals Author: Shaughnessy, Pat. Imprint: San Francisco : No Starch Press, [2014] Available at school book store. Also on Reserve at: Internet |
| Fundamentals of software engineering Author: Ghezzi, Carlo. Imprint: Upper Saddle River, N.J. : Prentice Hall, c2003. On Reserve at: Carlson Library Reserve Desk 2nd Floor Call Number: QA76.758 .G47 2003 |
Topics:
See schedule
Policies for CSC 2/453
The workload will be heavy. Be sure to read instructions for each assignment and exam carefully, start the assignment early, know where/when to seek help, and work with peers.
Grades will be released periodically to Blackboard, the University’s on-line course management system.
Attendance and Class Participation
Class attendance is mandatory. Please arrive on time. I expect to start at 3:25 sharp, and late arrivals disturb the folks who are already there. You are encourage to ask or answer questions in class. I may call on you just to know what you think. As a general rule, if there’s something you don’t understand, make me stop and explain it. There are probably a dozen people sitting around you who didn’t understand it either, but don’t have the nerve to say so. Likewise, if I’m belaboring something that everyone understands, prod me to move on.
I will assign reading before and after lectures. Reading is mandatory It includes all lecture slides released to Blackboard, and textbook chapters/sections listed on the first slide of each lecture. Keep in mind that the exams include topics covered in class and in the required reading.
Late Submission Policy
A student may have a total of two extra days in all assignments. They can be used as either a one-day extension for two assignments, or a two-day extension for one assignment. A student must inform the TA about the extension before the due time. No other late submission is permitted.
Academic Honesty
Student conduct in CSC 2/453 is governed by the College Academic Honesty Policy, the Undergraduate Laboratory Policies of the Computer Science Department, and the University’s Acceptable Use Policy for Information Technology. I helped to draft some of the descriptions. I believe in them strongly, and will enforce them aggressively.
The following are details specific to CSC 2/453.
Exams in CSC 2/453 must be strictly individual work.
Collaboration on programming assignments among team members is of course expected. Collaboration on assignments acrossteams is encouraged at the level of ideas. Feel free to ask each other questions, brainstorm on algorithms, or work together at a whiteboard. You may not claim work as your own, however, unless you transform the ideas into substance by yourself. Among other things, this means that you must leave any brainstorming sessions with no written or electronic notes—only what you carry in your head.
If you use the work of others (e.g., you download a function from the web at the last minute so that you can get the rest of your project working), then (1) either you must have the author’s explicit permission or the material must be publicly available, and (2) you must label what you copied, clearly and prominently, when you hand it in. You will of course get points only for the parts of your assignment that you wrote yourself.
To minimize the temptation to steal code, all students are expected to protect any directories or on-line repositories in which they do their work.
For purposes of this class, academic dishonesty is defined as
- Any attempt to pass off work on an exam or quiz that didn’t come straight out of your own head.
- Any collaboration on assignments beyond the sharing of ideas, unless the collaborating parties clearly and prominently explain exactly who did what, at turn-in time.
- Any activity that has the effect of significantly impairing the ability of another student to learn. Examples here might include destroying the work of others, interfering with their access to resources, or deliberately providing them with misleading information.
Note that grades in CSC 2/453 are assigned on the basis of individual merit rather than relative standing, so there is no benefit—even a dishonest one—to be gained by sabotaging the work of others.
I work under the assumption that students are honest. I will not go looking for exceptions. If I discover one, however, I will come down on it very hard. Over the past few years, I have submitted about a dozen cases to the College Board on Academic Honesty. All resulted in major penalties for the students involved.

Character Co-Occurrence in Shakespeare’s Sonnets and the Bible

This past summer, I’ve had the pleasure of working with Professor Chen Ding, Lucinda Liu, and Professor Daniel Gildea on an all-timescale co-occurrence analysis algorithm for optimizing microprocessor storage usage. This analysis can efficiently provide co-occurrence ratios for multiple timescales, which are time allowed for or taken by a process or sequence of events. The timescale is used to determine the likelihood of two events occurring together within that time window, giving a co-occurrence ratio. The developed algorithm is unique in its ability to calculate co-occurrence ratios for multiple timescales more efficiently than a brute-force method.
An initial pass of a trace of objects stores the distance between different elements of the trace. These distances can be used to see where gaps between trace objects are to wide to fall in the same time window, giving us a count of absence windows. The beauty of this algorithm is that the expensive operation, the initial pass of the trace, only needs to be done once to calculate timescale analysis of all pairs in a trace. By counting absence windows, joint and single frequencies can be determined.
We define the co-occurrence ratio to be the joint frequency of the pair divided by the single frequency of a given element. The given element is known to be present in a time window, meaning that the co-occurrence ratio represents the probability of finding the other element in the same time window. This makes the co-occurrence ratio a conditional probability.
This analysis was initially intended for use in optimizing processor cache utilization, by placing frequently co-occurring memory objects together in memory. The precise explanation can be found this paper. However, this concept can be extrapolated to any trace, whether it be a trace of words, or music notes, or pixels in a photo.
We applied our algorithm to Shakespeare’s Sonnets and the King James Bible, treating each character as a memory access taking one unit of time, skipping symbols and spaces. The letters, ignoring capitalization, are treated as memory accesses. We used timescales of 2, 5, and 10 to look at adjacent pairs, what one hand can type, and what two hands can type. Below are links to the data files and analysis of Shakespeare’s Sonnets and the King James Bible for multiple timescales using our algorithm:
| Shakespeare’s Sonnets | Timescale 2 | Timescale 5 | Timescale 10 |
| King James Bible | Timescale 2 | Timescale 5 | Timescale 10 |
The data can be interpreted as the conditional probability of seeing the second character given the first character is present in a given time window. Each individual character appears the same number of windows as the timescale size. So, if a second character is always adjacent to the first character on the same side the maximum co-occurrence ratio should be (timescale – 1)⁄timescale. The reason for this is that there will be one window that includes the first character but not the second.
For example, the character ‘q’ should always precede the character ‘u’. So, given a time window with ‘q’ the probability seeing ‘u’ in the same window should be at least (timescale – 1)⁄timescale. This means that all pairs with a co-occurrence ratio above that value have the second character on both sides of the first character like in the case of all word containing the substring “eve”. This is why for a timescale of 2 in Shakespeare’s Sonnets the pair (q, u) can be beaten by pairs like (x, e), but with larger timescales u’s from other words boost the (q, u) co-occurrence to put it in the lead.
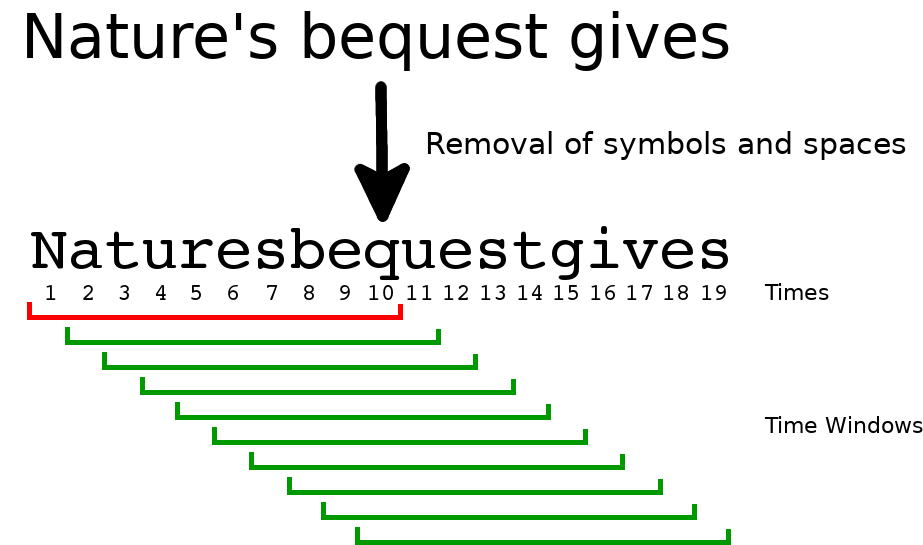
An example from Shakespeare’s Fourth Sonnet. Note how with the pair (q, u) the first window contains ‘q’ but not ‘u’ while the other nine windows have both characters. Also, the ‘q’ present in this trace appears in the same number of windows as the timescale size.
It is important to note that this method of co-occurrence analysis is not tallying frequencies. So when the pair (q, u) has the highest co-occurrence ratio, it does not mean that is the most common pair. Since the character ‘q’ is rarely used in the English language, its single occurrences are low, while its joint occurrences with the character ‘u’ are high. This is why for all the tests above many of the pairs with the highest affinities are uncommon consonants paired with a much more common vowel, like ‘e’. In both texts where the timescale 10 analyses were used, the top 10 pairs, excluding (q, u), have the character ‘e’ as a second character.
The data collected through this analysis has numerous uses outside of literature. The co-occurrence information can be used to evaluate the querty keyboard layout, or be used in speech therapy. Both the texts used here are from the same era, the turn of the sixteenth century into the seventeenth. It is possible that the character co-occurrence ratios could change with modern text or transcribed speech. Other than analyzing text, this analysis can be applied to images or videos for facial or object recognition.
I hope that this interesting re-application of memory layout analysis was entertaining to read about and I’d like to thank Professor Chen Ding, Lucinda Liu, and Professor Daniel Gildea for working with me on this project.
Image Sources: https://upload.wikimedia.org/wikipedia/commons/f/f6/Sonnets1609titlepage.jpg
https://upload.wikimedia.org/wikipedia/commons/e/e8/King-James-Version-Bible-first-edition-title-page-1611.png
Rocket Compiler Creator and Computer Science Professor Philip Sweany Dies

Philip Hamilton Sweany, PhD, beloved husband, brother, professor, colleague, and friend, died March 29, 2018 of neuroendocrine cancer.
(https://m.facebook.com/margaret.falersweany/posts/10213796046167865)
Born May 31, 1949 in Seattle, WA, Phil graduated from Washington State University with BS in Zoology in 1972. He worked in air pollution research for 10 years before returning back to WSU to study and received a BS in Computer Science in 1982. Phil married Margaret FalerSweany (Peggi) on January 27, 1980. He received an MS in 1986 and a PhD in 1992 in Computer Science from Colorado State University at Fort Collins, CO . Phil was a member of the computer science faculty at Michigan Tech University at Houghton, MI from 1991 to 2000, Texas Instruments’ Research and Development group in Dallas from 2000 to 2003, computer science and engineering faculty at University of North Texas in Denton from 2003 until his death in 2018.
Phil was my primary advisor during my MS study at Michigan Technological University from August 1994 to May 1996. I joined his Rocket Compiler research group as a research assistant almost immediately after I arrived at MTU from China. The computer science department was small and friendly. I still remember about half dozen faculty members and a dozen graduate students by name and face and recall vivid memories of the time. I remember Phil being extremely humorous. One couldn’t stop smiling and laughing while conversing with him. Also shortly after my arrival, my wife Linlin quit her graduate study at Peking U, and we started our married life. It was also the first time I heard about Internet, had my first email account (cding@cs.mtu.edu), and my first home page (viewable from anywhere in the world).
Phil’s research was compiling for instruction level parallelism. He and Steve Carr (who later became my co-advisor) put me to study a technique called software pipelining. Under their direction, I was exposed to research and developed several improvements. Through the work, the problem I found hardest and most intriguing was predicting the cost of a memory access. This problem was the seed that grew into my later work at Rice, which then led to the research, past and present, at Rochester.
Next year I attended my first conference, when Phil took the whole group on the road to Ann Arbor, Michigan to attend 28th MICRO, November 29 to December 1, 1995. My first paper was published shortly after at 29th Annual Hawaii International Conference on System Sciences (HICSS–29), January 3-6, 1996, Maui, Hawaii. Phil asked the department secretary to book the trip and told me that “unfortunately” to get “reasonable” airfare, I have to stay at Maui for the whole week! I remember being handed a thick stack of paper tickets (Houghton to Detroit to LA to Honolulu to Maui and back) and when there, stayed in the luxury Intercontinental hotel, with its miles of private white-sand beach. He put me in charge of renting a car (since I arrived first), although I have never rented a car before. Phil took Peggi and I to dinner in the first evening. We toured the rain forest together on the last day. In between I remember swimming in the ocean, locking the key in the car, taking a helicopter tour, and a number of other things I did for the first time.
My spoken English was so accented that it was indecipherable. Phil sent me to get help from Scientific and Technical Communication in Peggi’s department. After being tutored by a student named Lynn for both English pronunciation and writing, people began to understand what I was saying.
At MTU, there were just a handful of CS graduate students, and we had an active social life. There were multiple parties each year at faculty houses (or beach houses). Phil and Peggi hosted the Thanksgiving party in their house in Hancock. Theirs was my first encounter with not just the turkey but its many sides. Fellow graduate students organized movie nights in the winter and excursions in the fall. We spent a lot of time chatting when we sat in office, with Phil, Steve and other faculty occasionally walking by. I remember passing the written test at DMV (made just one mistake) after half hour crash course in the office. At MTU, graduate students stayed at the university apartments on the side of a hill next to campus. I was elected a student officer working with a committee selecting movies to run each month on the residential cable network. There was also much happened together with other Chinese students, e.g. the annual winter extravaganza. But in about two years when I graduated in 1996, I was thoroughly, properly, and happily Americanized.
My memories at MTU 22 years ago were among the fondest of the time when I was young and a student of Phil. I wrote the following comment yesterday after hearing the news:
Phil is my role model — a pure hearted scientist and teacher with uncompromising dedication to his research and students. I’m most fortunate to have him as my MS advisor and will continue to follow his example. His legacy lives through me and my students.
