
Lean Kernel Leaderboard
The Lean Kernel Arena (arena.lean-lang.org) is a public benchmarking and testing ground for different proof checkers (kernels) used in the Lean Theorem Prover. It runs a large suite of tests to check the correctness of each checker and reports their speed (⏱️) and memory usage (🧠), especially on large, real-world tests like mathlib (the comprehensive Lean mathematical library). Below is a screenshot of the leaderboard taken on April 29, 2026.
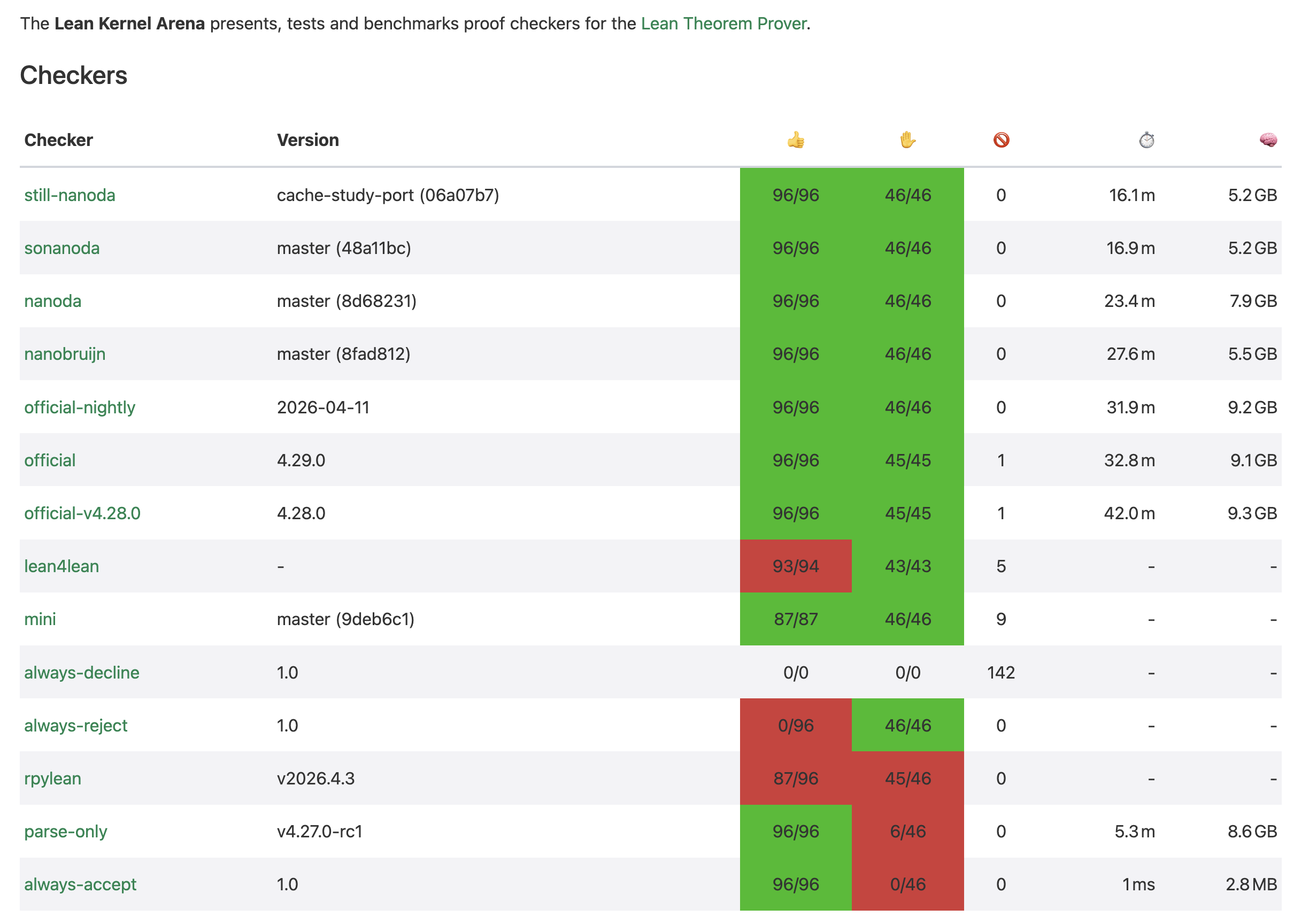
The public ranking includes the official kernels alongside community alternatives based on nanoda (implemented in Rust), lean4lean (written in Lean itself), and rpylean (using just-in-time compiled Python). My PhD student, Yifan Zhu, and I began discussing cache optimization for nanoda a week ago. By Monday morning of this week, Yifan’s version of nanoda had reached the top spot! The techniques he used will be the subject of an upcoming technical report. In this blog, I am merely reporting the numbers, with some context for readers who may not be familiar with Lean.
The leaderboard reports performance in total time, computed by dividing the total instruction count by a clock frequency. The instruction count does not consider the effect of caching. In addition, in multi-threaded kernels, the end-to-end time may be reduced significantly from parallelization. Yifan’s version shows only a 4% reduction in reported time, but in wall-clock time, it is substantially faster. On the benchmark machine running four threads, the wall-clock times are 4.9 minutes for Yifan’s kernel, 6.3 minutes for the second fastest, and 22 minutes for the official version. His Lean kernel is 22% faster than the second‑fastest kernel on the list.
Lean Applications
- Formalizing mathematics. Lean has been used to formalize mathematical proofs, from undergraduate topics (calculus, linear algebra) to ongoing research. An April 2026 analysis counted over 308,000 declarations, 8.4 million logical connections, and almost 1.4 million lines of Lean code.
- AI: Groups like Google DeepMind (with its AlphaProof system) use Mathlib as a benchmark and a knowledge base. AI models are trained on Mathlib’s data to learn how to reason and prove theorems automatically.
The most computationally demanding use cases are in the field of artificial intelligence, where AI models require generating and checking millions of potential proof steps. A faster kernel directly reduces the time and energy required to train and run these AI models. Beyond training AI, even standard automated proof tactics, e.g., simp (simplify) repeatedly applying rewriting rules to a goal, rely on kernel speed. With the rise of AI coding agents, the ability to quickly verify AI-generated code is crucial. An experimental AI agent was able to generate a 7,400-line verified embedded DSL over a single weekend, requiring the kernel to check thousands of lines of code for correctness on the fly (slides).
In industrial applications, speed is not just about cost-efficiency but about integrating verification directly into the development workflow. For example, AWS uses Lean to verify its Cedar policy system, ensuring no version ships unless all proofs pass. Microsoft uses Lean to verify its SymCrypt cryptographic library.
C++ vs Rust
I downloaded and counted the number of source lines in two kernels. The first is from https://github.com/leanprover/lean4.git in its src/kernel, counted using cloc:

This second is from https://github.com/ammkrn/nanoda_lib.git:

In reported measures, the official C++ kernels take 30 to 40 minutes and use over 9 GB of memory. The Rust-based kernels, in contrast, take as little as 16.1 minutes in Yifan’s version and use half as much memory. In parallel (4-thread) executions, the wall-clock time is 22 minutes for the official version, compared to 4.9 and 6.3 minutes for the top two Rust-implemented kernels. The parallel speedup, computed by the ratio of the reported time to the wall-clock time, is less than 2× for the C++ kernels and 3.3× for Yifan’s kernel. Overall, the Rust kernels execute fewer instructions and achieve greater parallel efficiency than their C++ counterparts.
* Corrected 5/12/2026: the time reported by the arena website is computed from the total instruction count, not based on measured CPU time.
