At Rochester we have studied the Dan-Towsley model multiple times. The description in their paper takes some effort to understand. Here we put down additional explanation for anyone who is interested in this model. The formulas included here are screen copies from the original paper.
In this problem, we have a collection of D fixed size items that share an LRU cache that can store B items. The D items are divided into k partitions. Each partition has D_k items and is accessed with the probability alpha_k. The access is assumed to be uniformly random within each partition. This corresponds to the Independence Reference Model (IRM) of King in 1971.
The LRU cache can be viewed as a stack with most recently accessed item at the top and least recently accessed item at the bottom. The cache state is defined by the content of these k positions. In this formulation, the state of each position is the partition id of the data item it stores.
We emphasize the use of partition id, For example for B=3, k=2, and D_1=2, a valid cache state may be (1, 1, 2), with both items of Partition 1 in the cache. This state records only the partition id, not the specific data item.
The following formula gives the set S of all possible cache states:
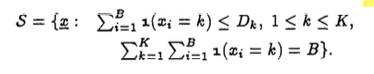
A valid state is a sequence of B positions with two constraints shown by the formula. First, for each partition k, the number of items in the cache cannot be more than its total number of items, D_k. Second, the total number from all partitions equals to B. Using the example B=3, k=2, and D_1=2 again, (1,1,1) would not be a valid state since it violates the first constraint of S.
King formulated the problem as a Markov Chain. A Markov Chain has a set of states and transition probabilities between the states. A common example is a drunkard’s walk. Let there be a set of bars. When leaving each bar, the drunkard has some probability to go to another bar. As a Markov Chain, each bar is a state. We are interested in computing the likelihood for each state. If we choose a state to compute the likelihood, we call this the target state. We use all the states that may transit into the target state. We call these preceding states. An equation can be constructed to show that the likelihood of the target state from the likelihood of preceding states and the transit probability from them to the target state. For the drunkard, we compute the likelihood that he visits a particular bar, e.g. Starry Night. The Starry Night is the target state. Its likelihood depends on a nearby bar, e.g. Joe Bean, so we can use the likelihood of Joe Bean times the probability that the drunkard would go from Joe Bean to Starry Night.
In the following, the target state x=(x_1, x_2, …, x_B). Its likelihood is computed from all possible preceding states. The first line of the equation shows the transitions due to cache hits, and the next two lines (a product of each other) the transitions due to cache misses.
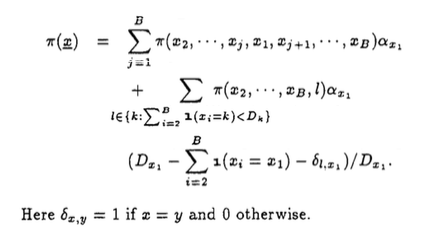
It is understandably non-trivial to solve a Markov Chain problem with this many states and transitions. King gave an exact solution which has a high computational complexity, exponential to D and B.
The Dan-Towsley model is an efficient approximation. It consists of almost entirely the following two equations. Eq. 2 is the key. In Eq. 2, p_k(j) is the probability of a Partition-k item is stored at position j, and r_k(j-1) the probability that if the item at position j-1 moves to j, the probability that this item is from Partition k. The Dan-Towsley model says that the two probabilities are equal.
The equation is recursive, since the two probabilities are used to compute each other. b_k(j) is the occupancy of Partition-k at stack positions up to j. It is computed from p_k(j). This occupancy is used to compute the likelihood that the miss happens for a Partition-k item. Eq. 2 computes r_k(j-1) by a ratio. The denominator is the likelihood of an access at stack position below j-1. This is a miss for B=j-1. The ratio is the likelihood that the miss happens for a Partition-k data item.
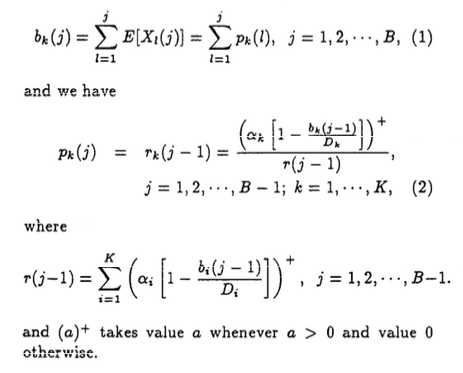
Eq. 2 is easily solvable by iterating starting from j=1 and p_k(1)=alpha_k.
More explanation is needed for Eq. 2. In the text, the paper says that r_k(j-1) is the probability that if the item at position j-1 moves to j, the probability that this item is from Partition k. In the equation, the ratio is likelihood that the miss happens for a Partition-k data item. The two are related in a subtle way — both are required for the occupancy stays the same before and after the miss.
Xiaoming Gu was the first to study and implement the Dan-Towsley model at Rochester. In 2008, he derived the distribution of reuse distance of random access, which corresponds to the solution of IRM for k=1. He then found the Dan-Towsley model and verified it as an efficient and accurate solution for any k.
The Dan-Towsley model is a brilliant solution based on the cache occupancy. Because of the IRM assumptions, the miss ratio can be computed from cache occupancy. The general solution needs to consider locality. The general problem is solved in recent years including the footprint based model developed at Rochester. It is extremely interesting to compare and contrast the occupancy-based model of cache sharing and locality-based models.
Asit Dan, Donald F. Towsley: An Approximate Analysis of the LRU and FIFO Buffer Replacement Schemes. SIGMETRICS 1990: 143-152
King, W. F., “Analysis of Paging Algo- rithms,” In Proc. IFIP Congress, pages 485- 490, Ljublanjana, Yugoslavia, aug 1971.
Gu, Xiaoming, “Reuse Distance Distribution in Random Access“, TR930, Computer Science Dept., U. Rochester, January 2008.
Acknowledgement. The explanation here is partly the result of discussion with Chencheng Ye and Rahman Lavaee. Chencheng’s research is supported by an IBM CAS fellowship, and Rahman by NSF CCF-1629376.

