Traditional polyhedral based tiling technology does not incorporate hierarchical memory such as grouped memory and threads. This paper proposed a two-step tiling approach, which firstly tile loops for nearest level memory and then treat the tiles as nodes, and tile them again for the farthest level memory. Authors apply their approach on stencil programs.
An example of tiling
Followed code is widely used by physicalists,
|
1
2
3
|
for(int t = 0; t < T; t++)
for(int i = 1; i <= N; i++)
A[t+1][i]=a*(A[t][i+1]-b*A[t][i]+A[t][i-1])
|
There are only 3 flow dependence, A[t+1][i] depends on A[t][i+1], A[t][i] and A[t][i-1]. The dependence graph is followed, each node stands for an instance(a specific iteration like t=3,i=2) of the loop:
Currently polyhedral based approach can figure out optimal tiling with specific shapes(only rectangle in tiled space), such as diamond in this case. This tiling has the minimal inter-tile dependence.

After tiled, tiles with same height can be executed in parallel.
Motivation
Consider a more complex architecture such as NUMA, in which threads are grouped into nodes, and each nodes contains its own cache. Threads can access cache on different nodes with a higher latency. Then locality will be diverse with ways of mapping tiles to nodes.
For example, the second top remarked tile and the third one depends on same tile, if both of them are mapped to different node, there will be remote cache access. So the ideal map is put them and the depended tile on the same node.
In this paper, authors treat these tiles as instances and apply tiling on them again. In this way they improve locality for architecture mentioned above, without hurting parallelism. For example, they apply tiles as followed figure:

Author grouped the tiles, let it is named as L1 tiles, into larger tiles, named as L2 tiles. Authors’ approach guarantee that:
1. There are no immediate dependence between L2 tiles
2. Tiles are mapping by L2 tiles
In this way, there would be no remote access intra L2 tiles and L2 tiles can be concurrently executed. Since polyhedral model is abel to figure out the optimal tiling which has minimal inter-tile communication, thus the L2 tiling can be optimal too.
Implementation
Authors use sophisticate tools including Cloog and pluto. Cloog generate code from polyhedral representation, and pluto figure out tiling with given constraints.
The algorithm is showing followed:
1. Figure out the optimal tiling L1(minimize inter-tile communication) which is able to concurrent start.
2. Consider L1 tiles as single instance, update loop domain and dependences
3. Apply polyhedral on updated loop to figure out L2 tiles, which is able to concurrent start and is optimal too.
Thinking and Discussion 1
Why polyhedral
Polyhedral model is a uniform model:
1. Can find transformation with varies constrains, such as validation for tiling or parallelism
2. Meanwhile, can figure out optimal transformation for different objectives, such as minimize inter-tile communication, minimize dependence distance.
Thus authors use polyhedral models to figure out a transformation that 1) is able to be tiled 2) has minimal communication, aka, best locality 3) can concurrent start
Why stencil programs
Polyhedral has a strong limitation that it only can be applied on specific codes, which is static control programs(SCOP). In brief, branches and memory accesses of SCOP are only related to predictable value, and them self can be statically predict too. For example, if(i != 3) in a loop, where i is a scalar.
Optimal Tiling
Even though polyhedral can figure out optimal solution in single step, but this paper employ polyhedral twice independently. This means the results can only be guaranteed to be a local optimal other than global optimal.
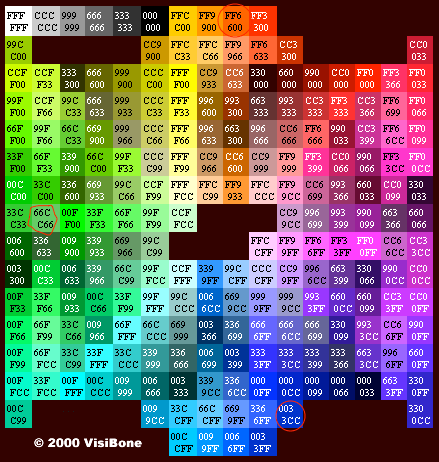

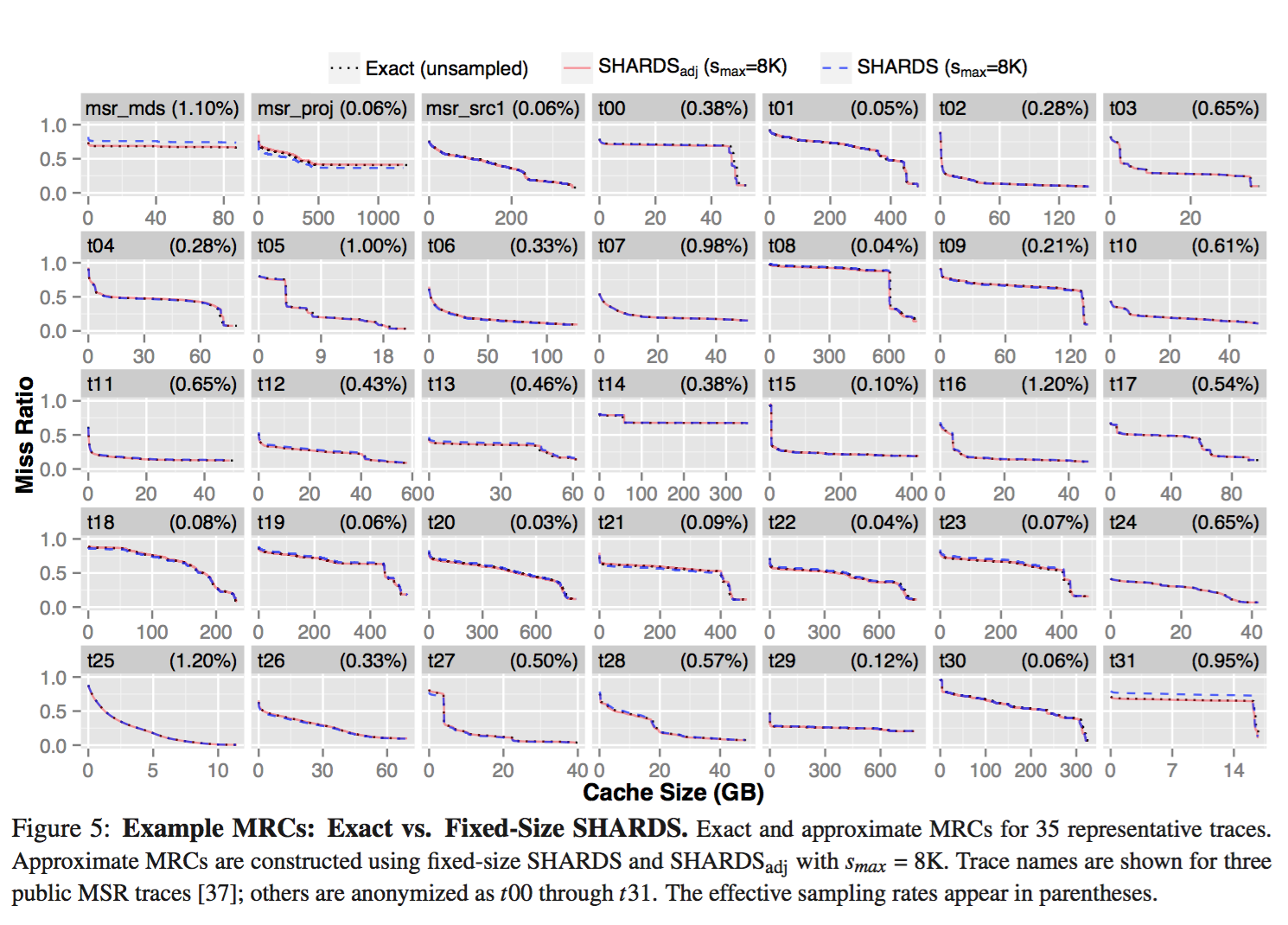





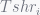 denotes execution time of program i while co-running and
denotes execution time of program i while co-running and 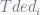 for solo-run. Then authors quantitive fairness to be
for solo-run. Then authors quantitive fairness to be