Seongbeom Kim, Dhruba Chandra and Yan Solihin
While programs running together, fairness become an important metric beyond throughput. In this paper, authors propose 1) a definition for fairness and 5 possible metrics. 2) 2 algorithms to improve the metrics through cache partition.
According to simulation experiments, authors show that 1) 2 of 5 metrics are not strong correlated to their definition of fairness, 2)LRU or Pseudo-LRU is not fair, 3) Improving fairness usually equal to improving throughput and 4)their cache partition algorithms improve fairness by a factor of 4X while increasing throughput by 15% on average.
More specifically, authors define ideal fairness to be

Where 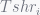
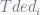
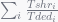
However, execution time is difficult to measure because of the lack of reference points in the execution. Thus 5 possible metrics are proposed in section 2.3. According to the correlation between these 5 metrics and fairness, turns out 2 metrics are not strong related to fairness and others are sufficient enough. At last authors selected the most correlated metric as following:
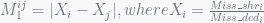
After metric is decided, authors proposed 2 algorithms to optimize fairness statically or dynamically. Both of them need additional hardware counter or functionalities. In brief, the static algorithm partition cache before programs running according to stack analysis results, which is gained through profiling. And the dynamic algorithm sampling programs periodically and adjust partition according to measures of sampling phase.
In evaluation, 18 2-programs pairs are tested, the 13 programs come from SPEC2K. A simulator is used with additional hardware counter and functionalities implemented.
Metric correlation is evaluated firstly. They figure out average correlation for all metrics and based on that, they select the best metric which has 94% correlation with fairness.
Then according to comparing between LRU and static partition, LRU produce very unfair sharing in 15 of 18 pairs, and in 3 pairs, LRU is better on fairness. Only in 1 pair, LRU gains better throughput.
The results for dynamic partition is similar. Even though Pseudo-LRU is slightly better than LRU on both throughput and fairness, but it still worse than dynamic partition with only 1 exception, in which PLRU is almost ideal.
Question:
1) For dynamic algorithm, why do not test M0 directly.
2) Not all pairs are tested(18/78)

Fairness is quantified so it can be compared. But as a single number (computed by adding a number from each member program), it is not clear how individual program performs. As a result, a better overall fairness may not mean better fairness when we consider all member programs.
In contrast, the notion of Pareto optimization I think is clearer. It means that each program cannot fall below a baseline.
But pareto shows the overall fairness but also do not show the fairness for each one. For example, we define the pareto as do not make other programs worse than 10%. Then if we have two solution, on make one program speed by 10%, and make other two program worse as 5% and 7%, the other one make other programs worse as 6% and 6%. So how to define which solution is better?
In Pareto, all these cases are fair but no one is more fair than another.