The increasing gap between memory latency and processing power requires a model under which we can decompose
these two. This book discusses models of memory hierarchy that suit this purpose.
The simplistic “external memory model” models the memory hierarchy as an internal fast memory and an external memory. The CPU operates on the internal memory. The external memory can only be accessed using I/Os that move B contiguous words between internal and external memory. The number of these I/O transfers defines the performance of an algorithm under this model, while the CPU performance is defined by the processing work on the internal memory.
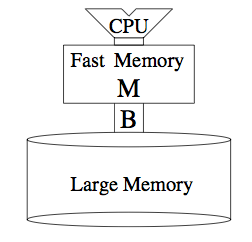
The external memory model
In a real memory hierarchy, a hardware cache uses a fixed strategy to decide which blocks are kept in the internal memory, whereas the external memory model gives the programmer full control over the content of the internal memory. This difference will probably not have devastating consequences as prior work has shown that in practice we can even circumvent hardware replacement schemes.
It is important to design algorithms that perform efficiently under this model. A relatively simple example illustrated in the book is implementing a stack. A naive implementation of the stack leads to O(N) transfers between internal and external memory in the worst case, where N is the number of stack operations (push and pop). However, using a buffer of size 2B (B being the block size), we can achieve amortized performance of O(N/B).
The book designs and analyzes efficient algorithms for several other fundamental problems such as sorting, permuting, and matrix multiplication.
The second model is the “cache oblivious model.” Algorithms designed for the external memory model need to know parameters of the memory hierarchy in order to tune performance for specific memories. Cache oblivious algorithms, on the other hand, don’t have any knowledge of the parameters M (cache size) and B (block size). Further, it assumes that the internal memory is ideal (a fully-associative cache with optimal replacement policy).
An example illustrated in the book is the “Van Emde Boas Layout” for binary search on balanced trees.
“Given a complete binary tree, we describe a mapping from the nodes of the tree to positions of an array in memory. Suppose the tree has N items and has height h = log N + 1. Split the tree in the middle, at height h/2. This breaks the tree into a top recursive subtree of height ⌊h/2⌋ and √N several bottom subtrees B_1 , B_2 , …, B_k of height ⌈h/2⌉. There are √N bottom recursive subtrees, each of size √N. The top subtree occupies the top part in the array of allocated nodes, and then the B_i’s are laid out. Every subtree is recursively laid out.”
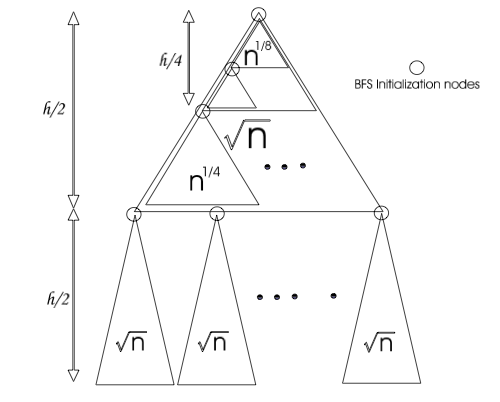
A view of the recursive layout
We now can analyze the number of cache misses for a binary search operation on a tree with a Van Emde Boas layout. If we denote by c(h) the number of cache misses on a tree of height h, we have:
c(h) = 2c(h/2) if h> lg(B)
c(h) <= 2 if h<= lg(B)
Therefore, we have c(h) = h – lg(B), which is lg N – lg B where N is the total number of nodes in the tree.