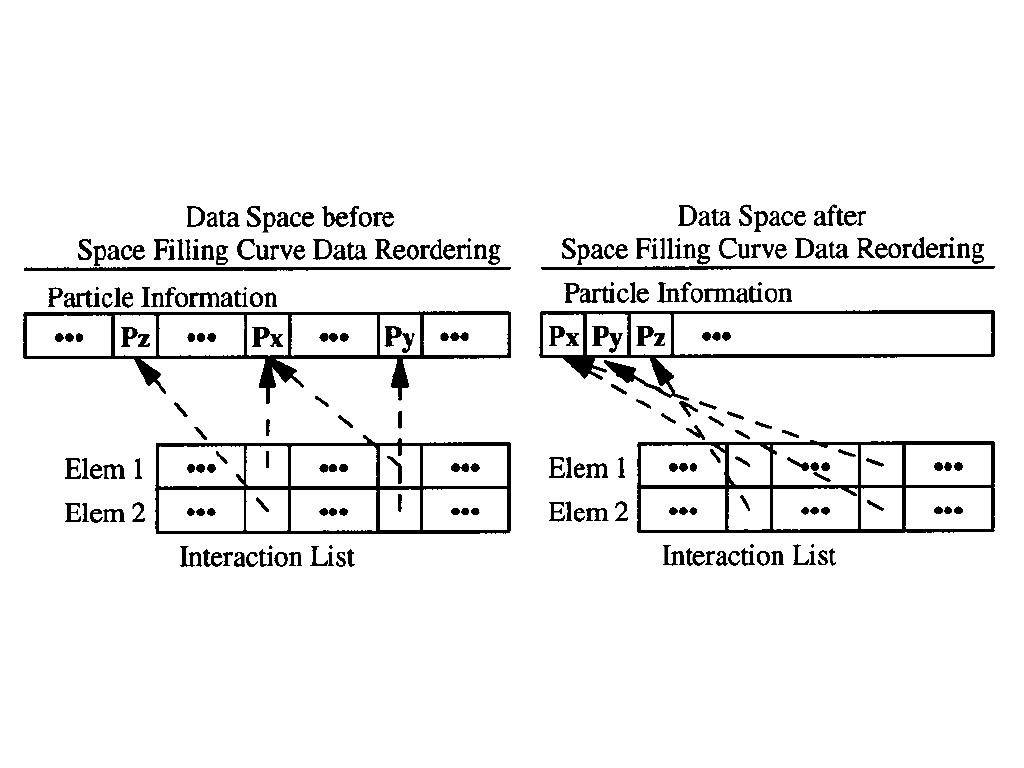
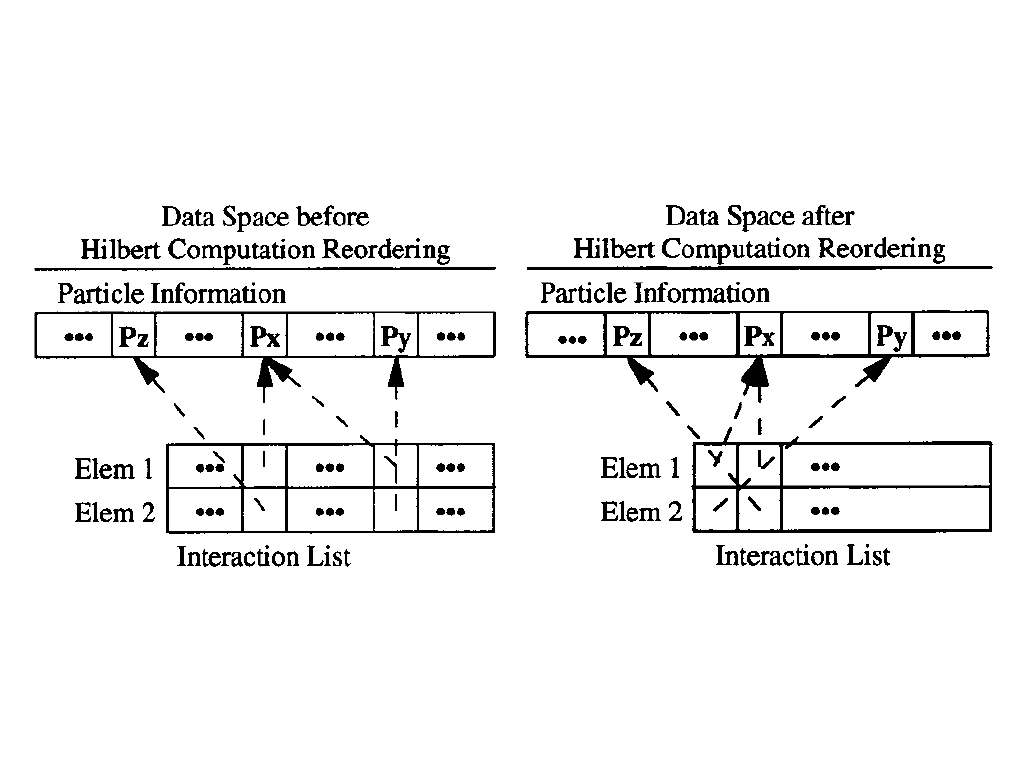
High memory utilization is especially important in DRAM-based storage systems. Evidence is obvious but ignored here. Traditional memory allocators use fixed and fine-grained size-class par- tition to seek an easy way to minimize internal fragmentation. However, under changing allocation patterns, the case of external fragmentation gets worse, so traditional memory allocators cannot meet the so strict requirement. Copying garbage collector is a common way to de-fragment memory slices, but it is time costly in original design. And also, pause times are another concern in garbage collectors. The paper claims that an ideal memory allocator for a DRAM-based storage system should have two properties: first, it must support copying objects to eliminate fragmentation; sec- ond, it must not scan global memory for bad time cost. Instead, it should support to incrementally scan. This paper proposes a log-structured approach for memory management in DRAM-based storages.
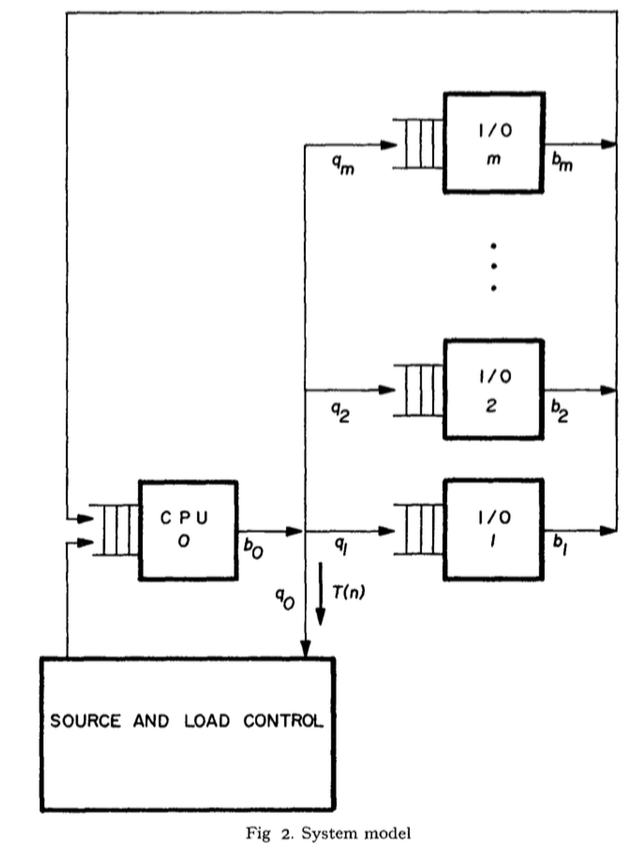
Each machine node in RAMCloud has a master part and a backup part. The master stores data for queries. The backup stores copies for crash recovery. The backup data is organized as a log for maximum efficiency. The master does so to match the backup. The log is segmented in a unit of 8MB. To quickly find an object in the master’s logs, a hash table is maintained in every master.
A log cleaner is used to reclaim free space that accumulates in the logs when objects are deleted. The log cleaner works on both masters and backups, which is called a two-level cleaning. For master, the logs are stored in memory, which has small capacity but high bandwidth; for backup, the logs are stored on disk, which has large space but low bandwidth. So different strategies are adapted in the two level cleaning of masters and backups. After reclaiming free space, the log cleaner moves the separated live data to new segments to compact memory. This meets one property of the allocator required by DRAM-based storage systems. The organization of log-structured memory allows the log cleaner to choose only a couple of segments every time cleaning to incrementally compact memory, which accomplishes the the second property the required allocator.
So basically the paper uses log-structured data organization plus an incremental copying GC. The disadvantage of log-structured data has much meta-data, which wastes space. To implement this system, the paper exploited many optimizations: two-level cleaning, parallel cleaning, resolution of hash table contention and concurrent log updates and deadlock avoidance. Overall, a lot of efforts are made to implement a simple-idea but solid system.