[Washington Post today (2/25/15)] “Bitter cold morning breaks long-standing records in Northeast, Midwest”
A “hot” concept in program optimization is hotness. Cache optimization, however, has to target cold data, which are less frequently used and tend to cause cache misses whenever they are accessed. Hot data, in contrast, as they are small and frequently used, tend to stay in cache. The “coldness” metric in this paper shows how the coldness varies across programs and how much colder the data we have to optimize as the cache size on modern machines increases.
For a program p and cache size c, the coldness is the minimal number of distinct data addresses for which complete caching can obtain a target relative reduction in miss ratio. It means that program optimization has to improve the locality for at least this many data blocks to reduce the miss ratio by r in size-c cache.
coldness(c, r) = (−1) ∗ (#uniq addr)
The coldness shows that if the program optimization targets a small number of memory addresses, it may only be effective for small cache sizes and cannot be as effective for large cache sizes.
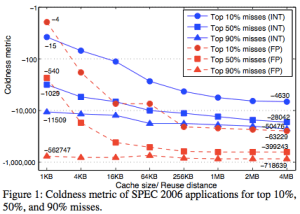
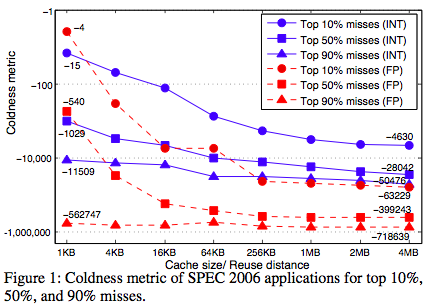
For 10% miss reduction, the coldness drops from -15 for 1KB cache to -4630 for 4MB cache in integer applications. In floating point applications, it drops from -4 for 1KB cache to -63,229 for 4MB cache. Similarly, for 90% miss reduction, the coldness drops from -11,509 to -50,476 in integer applications and from -562,747 to -718,639 in floating point applications. For the 4MB cache, we must optimize the access to at least 344KB, 2.4MB, and 5.4MB data to reduce the miss ratio by 10%, 50%, and 90% respectively. In the last case, the coldness shows that it is necessary to optimize for a data size more than the cache size to obtain the needed reduction.
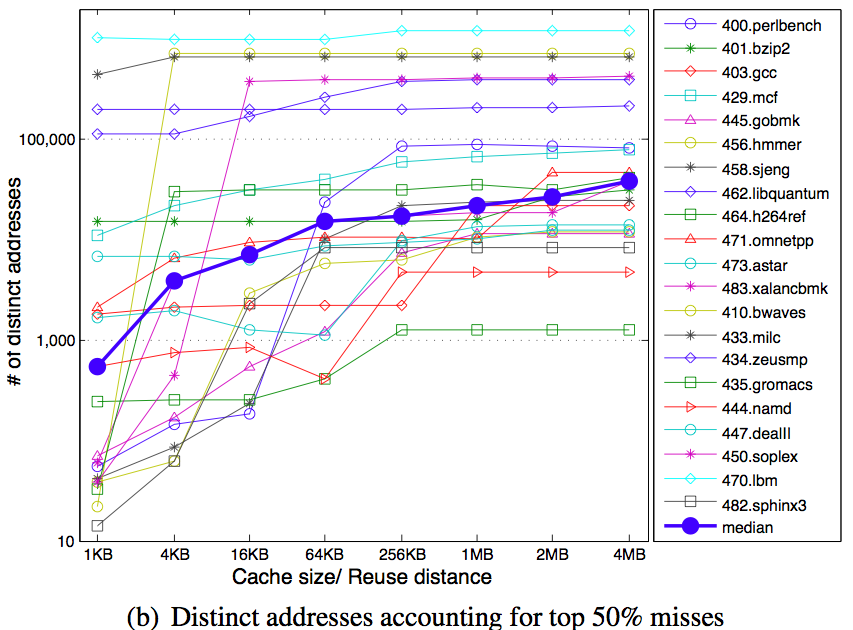
Next is the experimental data that produced these coldness data. It shows the minimal number of distinct addresses that account for a given percentage of cache misses.
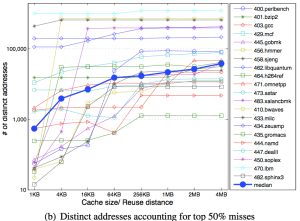
The average number of most missed addresses increase by about 100x for top 10% and 50% misses as the cache size increases.
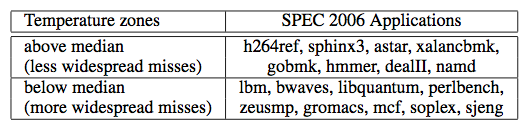
Based on the individual results, we classify applications into two groups. Applications that are consistently colder than the me- dian are known as below median cold and applications that are consistently not as cold as the median are known as above median cold applications.

Two Related Metrics
Program and machine balance. The limitation can be quantified by comparing program and machine balances [Callahan+:JPDC88]. For a set of scientific programs on an SGI Origin machine, a study in 2000 found that the program balances, ranging from 2.7 to 8.4 byte-per- flop (except 0.04 for optimized matrix multiplication), were 3.4 to 10.5 times higher than the machine balance, 0.8 byte-per-flop. The maximal CPU utilization was as low as 9.5%, and a program spent over 90% of time waiting for memory [DingK:JPDC04].
A rule of thumb is that you halve the miss rate by quadrupling the cache size. The estimate is optimistic considering the simulation data compiled by Cantin and Hill for SPEC 2000 programs, whose miss rate was reduced from 3.9% to 2.6% when quadrupling the cache size from 256KB to 1MB.
[More on weather from today’s Washington Post]
“Tuesday morning lows were running 30 to 40 degrees below average from Indiana to New England. Dozens of daily record lows fell Tuesday morning, by as much as 20 degrees. … A few readings have broken century-old records, including those in Pittsburgh; Akron-Canton, Ohio; Hartford, Conn.; and Indianapolis. In Rochester, N.Y., the low of minus-9 degrees tied the record set in 1889. Records in Rochester go back to 1871. … The western suburbs of Washington had their coldest morning in nearly two decades. Dulles International Airport set a record low of minus-4 degrees, which broke the previous record set in 1967 by 18 degrees.”