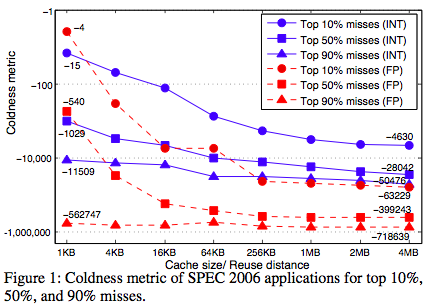
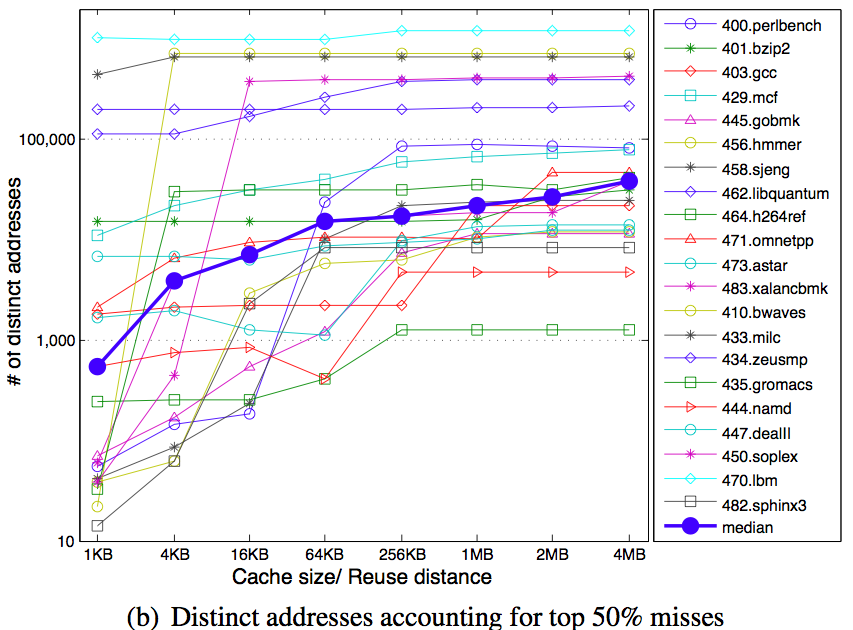
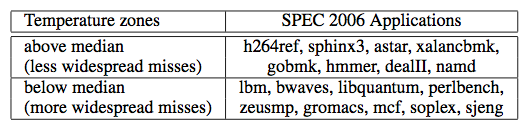
Robert Morris headed the performance analysis group at IBM. He and his co-authors write with clarity, precision, and good “locality” in that the paper is organized so each part serves a specific purpose small enough to understand easily. Two of the papers are as follows, along with the abstract.
[WangM:TOC85] Load Sharing in Distributed Systems
An important part of a distributed system design is the choice of a load sharing or global scheduling strategy. A comprehensive literature survey on this topic is presented. We propose a taxonomy of load sharing algorithms that draws a basic dichotomy between source-initiative and server-initiative approaches. The taxonomy enables ten representative algorithms to be selected for performance evaluation. A performance metric called the Q- factor (quality of load sharing) is defined which summarizes both overall efficiency and fairness of an algorithm and allows algorithms to be ranked by performance. We then evaluate the algorithms using both mathematical and simulation techniques. The results of the study show that: i)the choice of load sharing algorithm is a critical design decision; ii) for the same level of scheduling information exchange, server-initiative has the potential of outperforming source-initiative algorithms(whether this potential is realized depends on factors such as communication overhead); iii) the Q-factor is a useful yardstick; iv)some algorithms, which have previously received little attention, e.g., multiserver cyclic service,may provide effective solutions.
[WongM:TOC88] Benchmark Synthesis Using the LRU Cache Hit Function
Small benchmarks that are used to measure CPU performance may not be representative of typical workloads in that they display unrealistic localities of reference. Using the LRU cache hit function as a general characterization of locality of reference, we address a synthesis question: can benchmarks be created that have a required locality of reference? Several results are given which show circumstances under which this synthesis can or cannot be achieved. An additional characterization called the warm-start cache hit function is introduced and shown to be efficiently computable. The operations of repetition and replication are used to form new programs and their characteristics are derived. Using these operations, a general benchmark synthesis technique is obtained and demonstrated with an example.