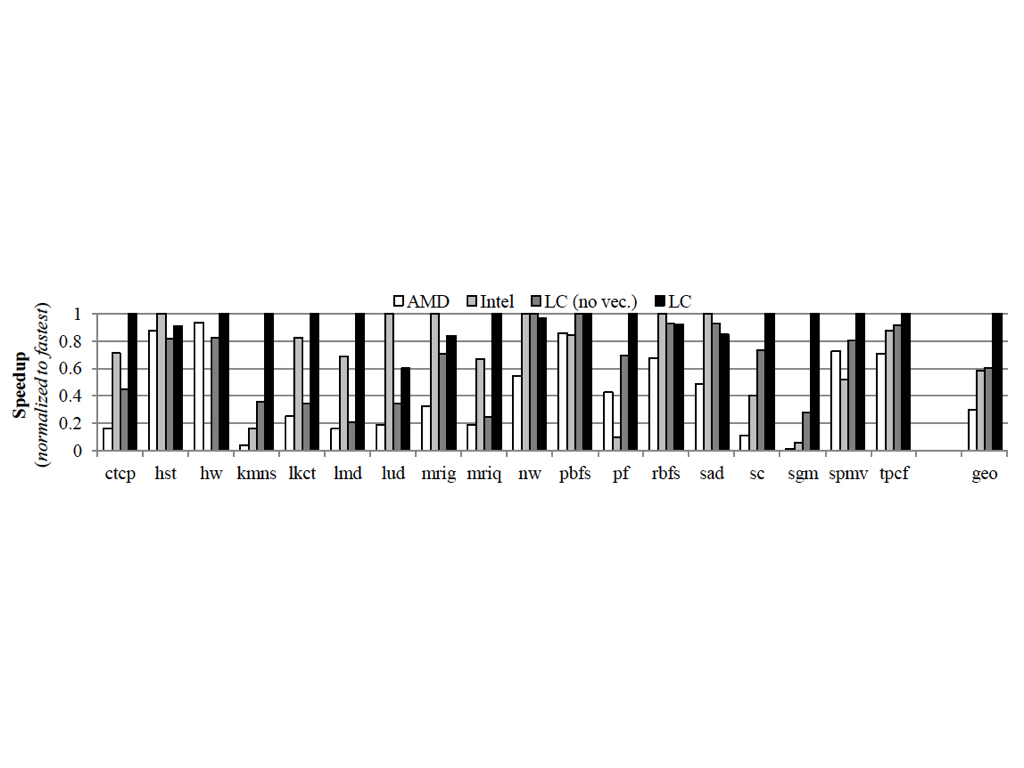
Hee-Seok Kim from UIUC proposed locality centric threads scheduling method for parallel code with bulk-synchronizations and a source-to-source compiler to transform the OpenCL Kernel code. And their approach can achieve geomean speedups of 3.22x compared to AMD’s and 1.71x to Intel’s implementations.
Heterogeneous platforms are becoming more and more common in today’s computing devices. A heterogenous computing model (language) is to allow single programs run on devices with different architectures. Beyond that, In order to make a single version of code achieve a satisfiable performance on all devices, compilers and runtime systems are designed to make it possible.
OpenCL is one the famous programming model which support a lot of total different architectures (CPU, GPU, MIC, FPGA), it has an abstract execution model which can isolate the difference of the hardware. The abstract execution platform contains multiple computing unit and each computing unit has multiple processing elements. The program itself is mapped into multiple work items (threads) which are grouped into work groups (thread block). each work group will be mapped into a single computing unit and all the work items in the same work group can be synchronized (bulk synchronization) and share memory.
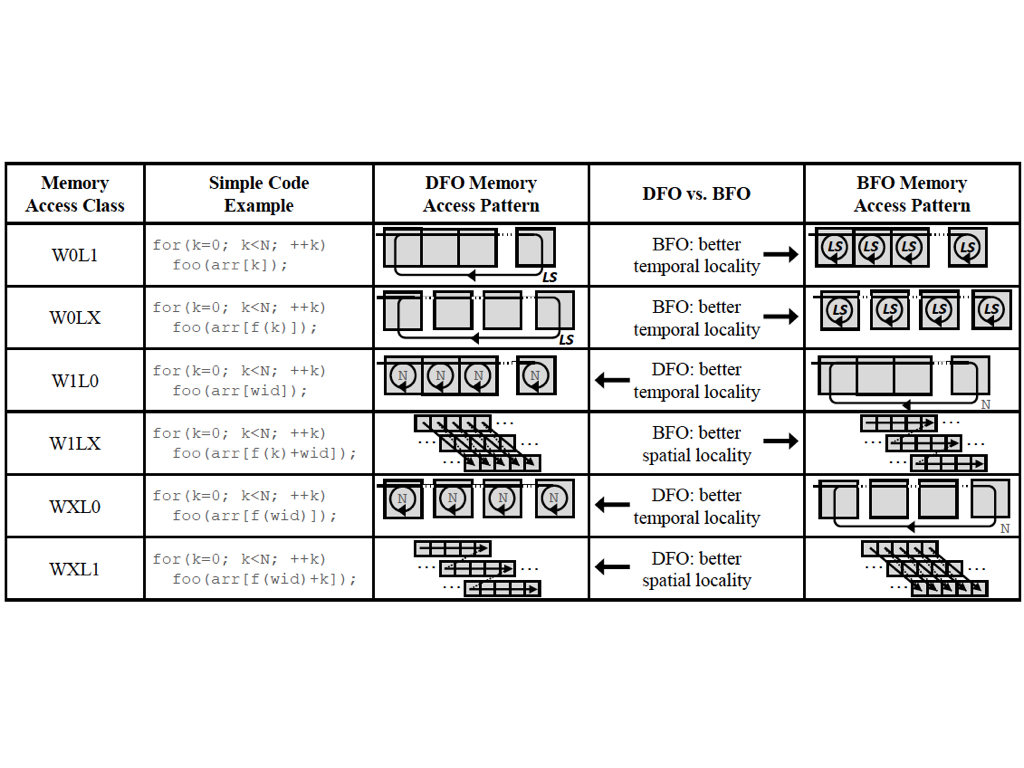
As CPU have a larger thread switch overhead, so what they do is to use compiler to coalesce the work items in the same work group. And the coalesced order is based on the data locality of the program. First, they classify the memory access pattern (inside the loop) into 6 patterns. “W” is work item, “L” is Loop iteration. “0,1,X” means stride. Then compare the memory access stride of work item and the stride of loop index to choose a scheduling method. If the stride of work item is smaller, then the preferred scheduling will be to traverse broadly over the work item ids before continue the next iteration, so Breadth First Order (BFO) is chosen. If the stride of loop index in smaller, then the preferred scheduling will be traverse deeply over the loop iteration space before start the next warp, so Depth First Order (DFO) is chosen.
table here
Examples for locality centric scheduling:
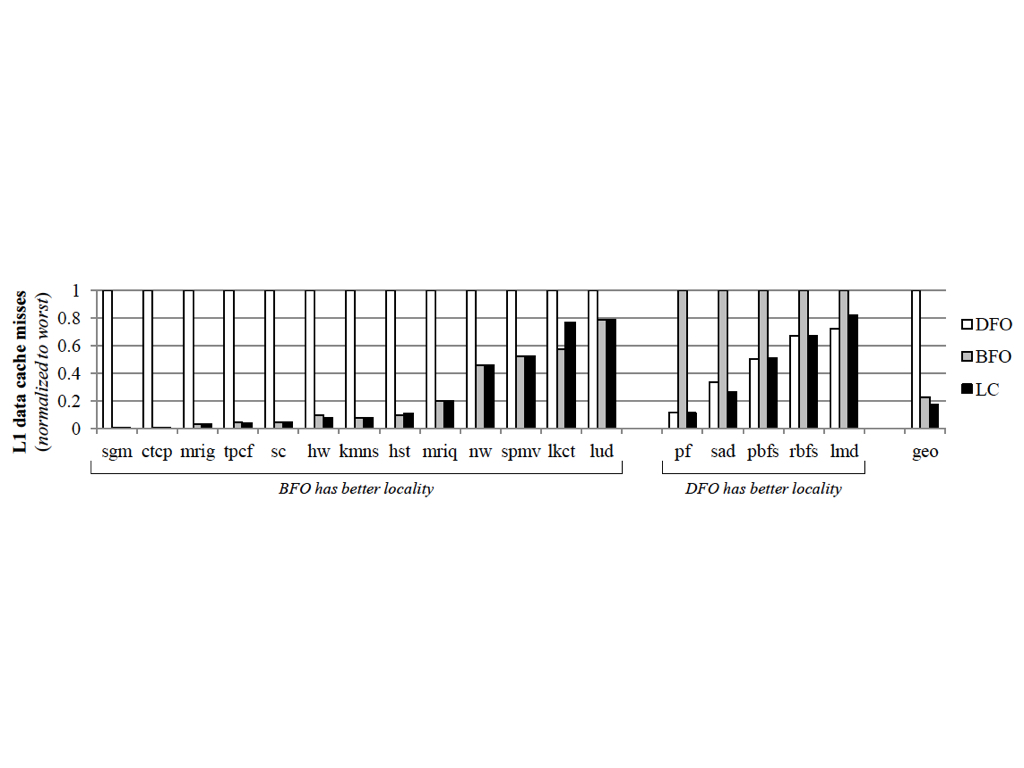
Evaluation:
They compared their implementation (LC scheduling) with the pure DFO and BFO scheduling, in general LC is better.
They also compared the LC with AMD and Intel’s compilers