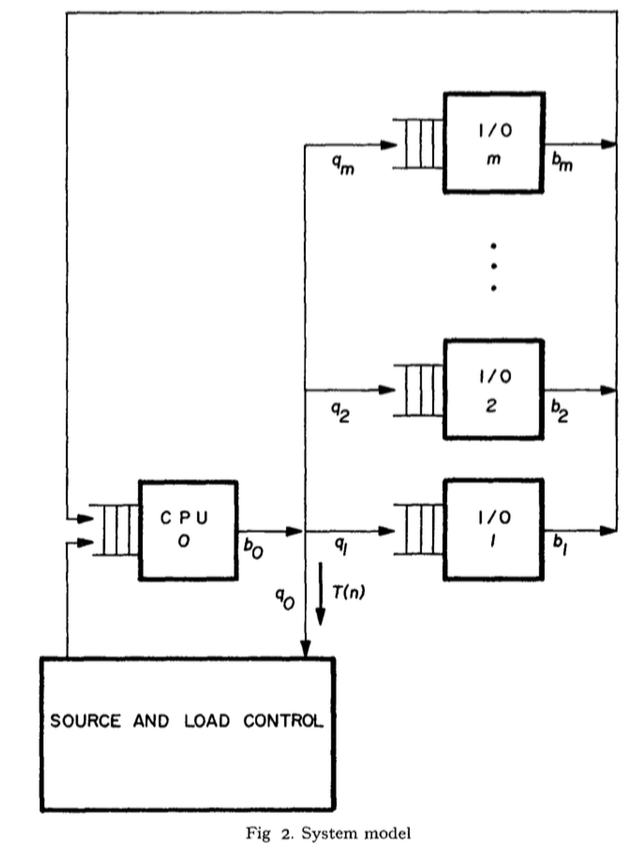
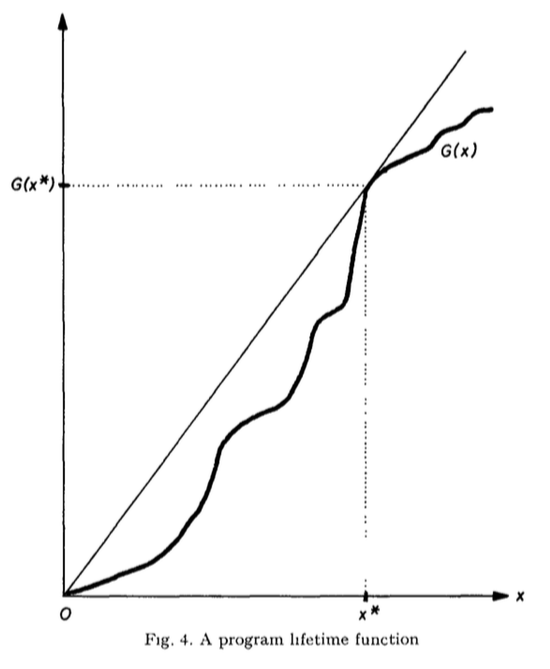
In my last post I talked about the space-time throughput law, and how it can be used to maximize throughput (by minimizing memory space-time per job). This concept is Denning, Kahn and Leroudier argue in their 1976 paper “Optimal Multiprogramming” for the “knee criterion”, which I wrote about on April 30, 2015. In summary, a program’s lifetime curve plots the mean time between misses (called the lifetime) against its mean memory usage. The knee criterion recommends operating a program at the knee of its lifetime curve.
The Knee Criterion
The argument in “Optimal Multiprogramming” is as follows. Let “virtual time” be counted in memory accesses. Using the following variables…
- K: The number of page faults during a program’s execution
- x: Its mean memory usage
- G(x): Its lifetime function (or mean virtual time between faults, for a given x)
- D: The fault delay (in virtual time – i.e., how many accesses could have been satisfied if it weren’t for the miss.)
The program executes in time approximately KG(x) + KD, and totals KG(x) references. The memory space-time per reference is can then be written

The knee of the lifetime curve (see Fig. 4 below) minimizes x/G(x), and thus “the component of memory space-time due to paging”.

I have one question about this argument though: Why are we only concerned with the one component [x/G(x)]*D? The space-time throughput law implies that we should minimize the space-time per job, not the component of space-time per job due to paging, right? This argument doesn’t make intuitive sense to me.
Processor-Utilization and Memory
Consider a system with multiple CPUs sharing cache, and a pool of jobs to be run. The goal is to maximize the job throughput, which can be done by maximizing the fraction of processor time spent active and not waiting for misses. For each processor i, let’s call this quantity the processor-memory utilization:

where Di is now the average delay due to a miss for the program on processor i. Modern processors amortize the effects of LRU cache misses (or what would be LRU cache misses) using optimizations such as superscalar, out-of-order execution, load/store forwarding and prefetching, but I am making the assumption that a program’s total run time can be expressed in the form KG + KD, where K is the number of cache misses, G is the lifetime (inter-miss time), and D is a correlation coefficient, all based on a given caching policy.
Note that the utilization here now measures accesses per time, where in the above argument for the knee criterion, space-time per access was used. Utilization per space is the multiplicative inverse of space-time per access. Following the policy of maximizing space-time per job, we could maximize utilization per space, but with a fixed total memory size, that is equivalent to simply maximize utilization.
When the processor is idle (no job is assigned to it) its processor-memory utilization is taken to be zero. Now, if we define the system processor-memory utilization as the sum of that quantity for each CPU:

If the miss ratio is the multiplicative inverse of the lifetime function, then this becomes

where, as before, the utilization of processor i is taken to be zero when no job is assigned to the processor.
Up to this point, we haven’t needed to mention what caching policy we are using. However, the miss ratio of each program is dependent on that. For global LRU, the miss ratio can be calculated with natural partition theory. For partitioned LRU, it can be calculated with HOTL. For WS, the lifetime (inter-miss time) function may need to be monitored during program execution.















{kind=link}