Logic in Coq. Logical Connectives: Conjunction, Disjunction, Falsehood and Negation, Truth, Logical Equivalence, Logical Equivalence, Existential Quantification. Programming with Propositions. Applying Theorems to Arguments. Coq vs. Set Theory: Functional Extensionality, Propositions vs. Booleans, Classical vs. Constructive Logic.
Inductively Defined Propositions. Induction Principles for Propositions. Induction Over an Inductively Defined Set and an Inductively Defined Proposition.
The Curry-Howard Correspondence. Natural Deduction. Typed Lambda Calculus. Proof Scripts. Quantifiers, Implications, Functions. Logical Connectives as Inductive Types.
It is my pleasure and honor to succeed Michael Scott as the chair. We are an elite research department in a private university that excels in undergraduate education and advanced research. Our faculty size, 21 tenure track and 6 instructional, is substantial in size to lead research and teaching across broad topics in AI/HCI, systems, and theory, yet small enough to operate by consensus. This combination of size and strength is unique, making it the best department for me for over two decades. My goal for the three-year term is to maintain its quality, spirit, and momentum.
This is the year the department turns 50 and simultaneously grows young again. The department has grown steadily under Michael’s stewardship in the past four years, and Sandhya Dwarkadas’s before that. For the first time in over two decades, junior faculty outnumber senior faculty. The staff size is at an all-time high, and most administrative staff are recent hires.
As part of the Meliora weekend, we celebrated our 50th anniversary with morning talks, an afternoon meet-and-greet, and an evening reception at the Hawkins-Carlson room at the library. Registration was beyond capacity for all three events, and the evening cocktail party was standing-room-only with a full house. Thanks to all who came to the celebration, especially our four keynote speakers: Danny Sabbah reminisced about how he fell asleep in his breakfast bowl after the grueling first-year exams; Amanda Stent defined modern AI as solving problems unsolvable by algorithms and then took questions for 24 minutes; Chris Stewart was as inspiring in his work, digital agriculture, as he was to me when he was in my advanced compiler class; and Michael Scott more than anyone embodied the department’s distinguished identity and stature, with grace and humor.
In the last year we have graduated 123 students with BA and BS degrees, 26 MS degrees, and 3 PhDs. While the PhD count is low after last year’s 20, two recent graduates started tenure track professorships, Jie Zhou (MS ’17, PhD ’23) at George Washington University and Michael Chavrimootoo (BS ’20, PhD ’24) at Denison University. Both worked with me on research prior to their successful PhD work – Jie Zhou on secure computing systems, directed by John Criswell, and Michael Chavrimootoo on computational social choice, directed by Lane Hemaspaandra. Michael also runs half marathons.
In technology, this is the year of generative AI. URCS was founded as an AI department, with five AAAI fellows on faculty over the years, including Henry Kautz, who was AAAI President from 2009 to 2014, and Len Schubert, who retired this summer after 37 years on the faculty most prominently in the field of common sense reasoning. The research of over half the department’s faculty is related to AI, with six professors specializing in core areas of statistical AI such as computer vision, natural language processing, graph neural networks, and machine learning theory, and teaching in these subjects. Next year, we plan to hire at least one additional AI faculty member.
We are teaching a large number of students about AI. By my count, in the third week into Fall 2024, the department is teaching ten advanced courses (200 level or higher, 13 of which are cross-listed) to a total of 491 students, including 129 in CSC 242 Introduction to AI taught by Thaddeus Pawlicki; 99 in CSC 245/445 Deep Learning by Chenliang Xu who created the course in 2017; and 23 in CSC 511 Large Language Models, new this year created by Hangfeng He. Additional courses are offered by Data Science and Brain and Cognitive Science and have CS course numbers.
Every year, our undergrads compete in the International Collegiate Programming Competition (ICPC). This year’s lead team consisting of Zeyu Nie ’24 (computer science and applied math), computer science master’s student Xiaoou Zhao, and Yan Zou ’27 (computer science) placed third in the regional, behind MIT and Harvard, and 17th in the North American Championship, just behind Michigan and Cornell. Despite competing against primarily schools with vastly larger CS programs, our students won their spot in the World Finals. In national contests, CS junior Cole Goodman won the NCAA Division III championship and qualified for the US Olympics Team Trials. Cole is the first Rochester student to do so since 1988 and the only athlete who has taken my course and learned computer organization and RISC-V assembly programming.
The department continues to work to broaden CS participation. Among the activities, ten students, led by our newest faculty member Yanan Guo, attended the Grace Hopper Celebration in October in Philadelphia, the largest gathering of women technologists worldwide. One month earlier, Fatemeh Nargesian led a ten-student group to San Diego, the largest in the department’s history, to the Tapia Conference, which annually brings together students, researchers, and professionals in computing from all backgrounds and ethnicities.
Last but not least, this is the year of charity giving. Danny Sabbah established the first endowed professorship in Computer Science with a generous $2M donation. Rick Rashid started the CS50th fund with a contribution of $100K. Since September 1, 2023, forty-seven other donors, mostly our graduates and their family members, have contributed a total of $38K. Charity is good for the soul. Intelligence may be mechanized, but the soul is uniquely human. The generous financial support is a confirmation from our alumni and others who care about the department, its mission, and its direction.
All that we do draws inspiration and strength from our alumni and friends. We are grateful for all your support.
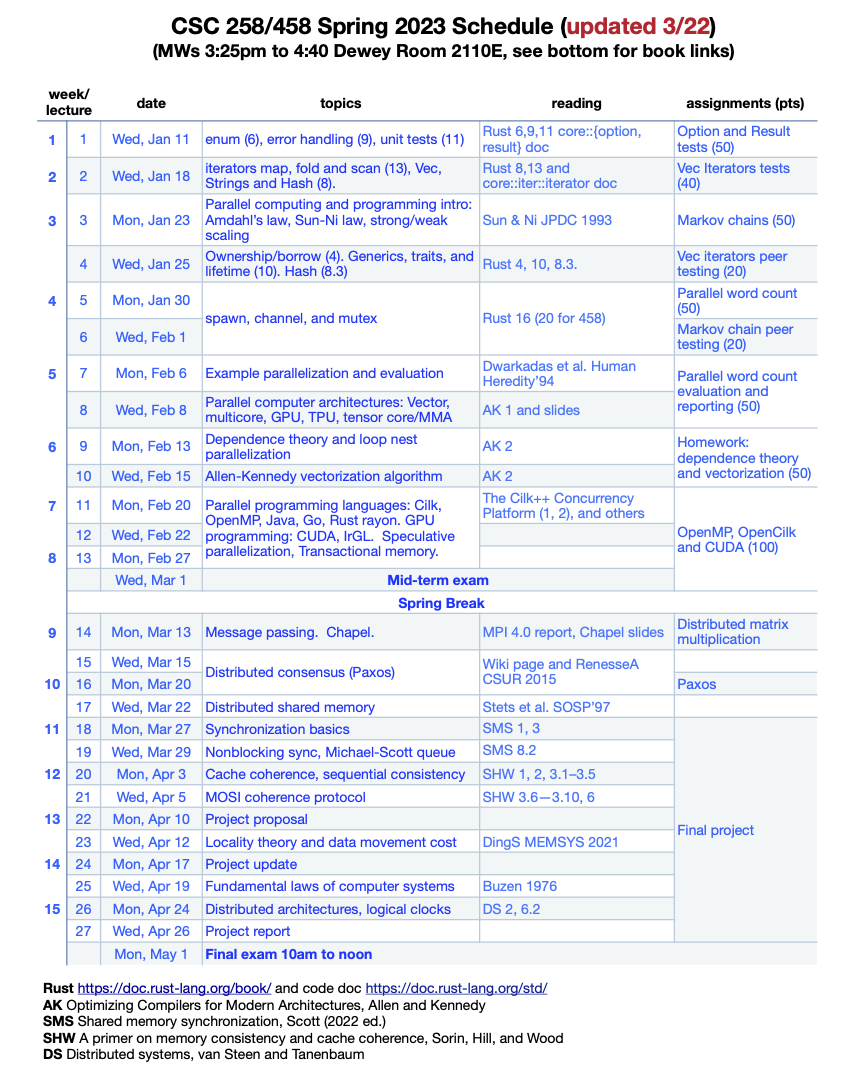
This is a course required for the Bachelor of Science degree in Computer Science at the University of Rochester. A graduate must understand in depth the underlying physical reality which the virtual world including AI is built and depends on, i.e. the fundamentals of modern computer organization, including software and hardware interfaces, assembly language and C programming, memory hierarchy and program optimization, parallelism and operating systems. The textbooks are listed here.
There are two aspects for such a course in an elite research department like mine. First, the teaching focuses on fundamentals and goes in depth, which sets a high standard but this requirement is necessary for students to learn advanced subject courses later. Second, the material is updated often and part of it even experimental. In prior semesters, my colleagues Prof. John Criswell has emphasized on assembly and operating systems, Prof. Yuhao Zhu on gates and circuits, and Prof. Sree Pai on automatic (bit operation) correctness checking. My main change is the ISA.
RISC-V Instead of x86
Instruction Set Architecture (ISA) is essential in a BS CS degree and must be learned in this course which may be most hated material by a good number of students especially who have no prior knowledge of computer hardware. In my ancient PKU years, I learned Zilog Z80 (a microcontroller) and taught MIPS (classic RISC) and x86 (Intel/AMD) last time in this course in 2012. For the 2024 course, I evaluated Arm (Apple silicons) and the newest RISC-V. RISC-V is “open-source hardware” which means free for anyone to use. The course has the room to teach just one ISA; otherwise students will rebel.
I had a year to prepare for the course and tested this idea first before deciding on this significant change — This year’s students were the first (in Rochester) to learn RISC-V.
My NSF project with RIT has synthesized a RISC-V processor (papers here and here). I consulted my RIT collaborators who told me “x86 is too complex”, Arm is better but has “a lot of corner cases”, and for RISC-V, “I like it enough.” I learned about RISC-V over the years from computer architects to know the ISA is a good design, e.g., the first time in ASPLOS PC in 2019, but the RIT feedback made me think that the ISA is practical and learnable. The next question is whether it is teachable in a required undergrad class.
I purchased five or six single-board computers in both Arm and RISC-V and have them installed. Department staff Ian Ward installed Linux on Lichee-Pi 4A which has a quad-core processor, a GPU, and 8GB RAM for $130. The Arm processor (Raspberry Pi 4A) is weaker and does not run Linux.
My graduate TA Yifan Zhu (SchrodingerZhu on GitHub) installed the complete tool chain to compile and run RISC-V programs (in QEMU) on undergrad server (Intel) machines.
I found the 2024 textbook on RISC-V as recommended by the RISC-V foundation. The book reads well and covers the core knowledge: data representation, binary file and assembly, registers, data movement and control flow, application binary interface (ABI), all in 100 pages.
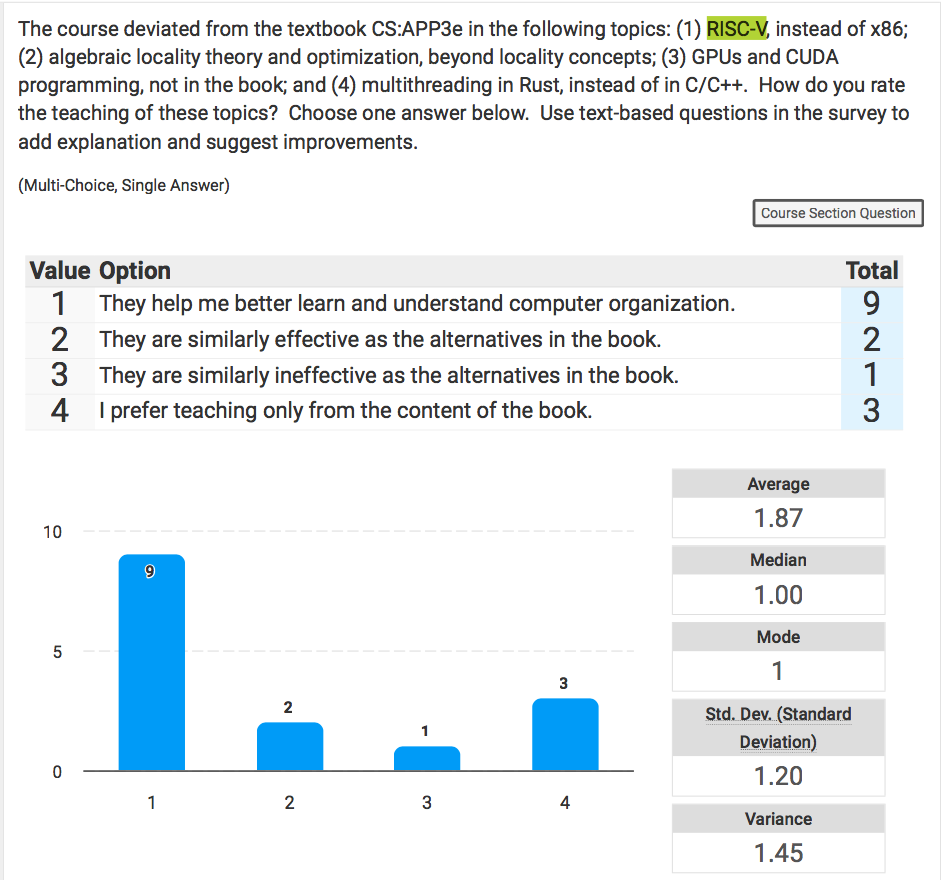
Here is the result. I summerized four changes in the following question (I created) in the Course Evaluation. Here are the question and the 15 responses:
RISC-V is newer and better designed, first with a core and then a series of extensions. The book covers RV32I, the core ISA. It is challenging to learn but learnable, unlike x86 which is too unwieldy, but it is 100 pages of material. Many students read the book and learned. They crossed a threshold of knowing the complete core, which they cannot do from learning x86.
Reading Books instead of Studying for Exams
At last semester’s CS Undergrad Town Hall where most CS faculty sat to listen to students’ feedback. One is that the department changes instructors of a course, and the exams are completely different from past years. I responded that a course teaches a subject, not a subject taught in a particular way and definitely not just exams. Exams are not the goal of learning or teaching, they are the feedback for both students and their teacher.
For this course, Prof. Zhu has made available past exams, problem sets, and their solutions (which I linked to in my course page). One can learn by studying these but shouldn’t use them as the primary source. Instead, students should learn by reading the textbooks. An important use of my lectures is to motivate students to read, show organization so they have mental map going in, and explain tricky/difficult examples and parts. When I find students don’t read textbooks, I use the lecture to read the book with them. My goal is for students to read the book and read it multiple times. The RISC-V book has the full content, updated, and readily accessible online.
The next and last 25 pages of the RISC-V book covers system-level programming (not covered in the course) but reading them (if/when they need to) would be a breeze once a student reads the first 100 pages.
In-person instead of Off-line Grading
The class has 64 students. 89 students registered, 21 dropped, and 5 withdrawn. Multiple students told me that they liked the course but felt not sufficiently prepared and will take the course next semester.
I myself cannot give every student the time and attention they deserve. There is no self deception/illusion/delusion here. I hired seven undergrad TAs. To maintain consistency, they must be primarily responsible for grading. The last thing I should do is to cherry pick and over rule their work.
There are two challenges to project grading. Computer organization is standard material, and the solutions of pass assignments and projects are abundant on the Web. One may say that students who choose to copy solutions waste their time and learning opportunity so who cares, but these are young minds that are often immature, so I do care to at least make it hard for them to fall. Using RISC-V reduces the severity of the problem.
The new problem is ChatGPT and other AI tools which could program in RISC-V. My TAs solved the problem with in-person grading. Students are divided into four groups and come to a TA session each week. They were required to explain their solution. In home work, students wrote and ran RISC-V programs using an emulator. At grading time, TAs set up an actual RISC-V machine so students saw their programs running native and for real.
In one project, the binary bomb, Yifan created the setup that students had practice bombs but when they came to grading, they were given a new bomb to defuse in 15 minutes.
The Result
The end test of a course is how well students have learned after a full semester. There were a total of 869 points across all assignments and exams. The final score is the ratio of student’s points over this total number. Here is the distribution:
50 students scored 80% and above, and all but 7 students were 70% or higher. I had the most fun problem which was deciding between a B+ and an A- for the 8 students who were between 88.94% and 90.2%. This is much better than what I expected from such a difficult course. I remember telling my colleagues who were duly impressed by my students. I am still immensely proud of what they have done.
Parting Thoughts
“One might as well say he has sold when no one has bought as to say he has taught when no one has learned.” — John Dewey in Logic The Theory of Inquiry
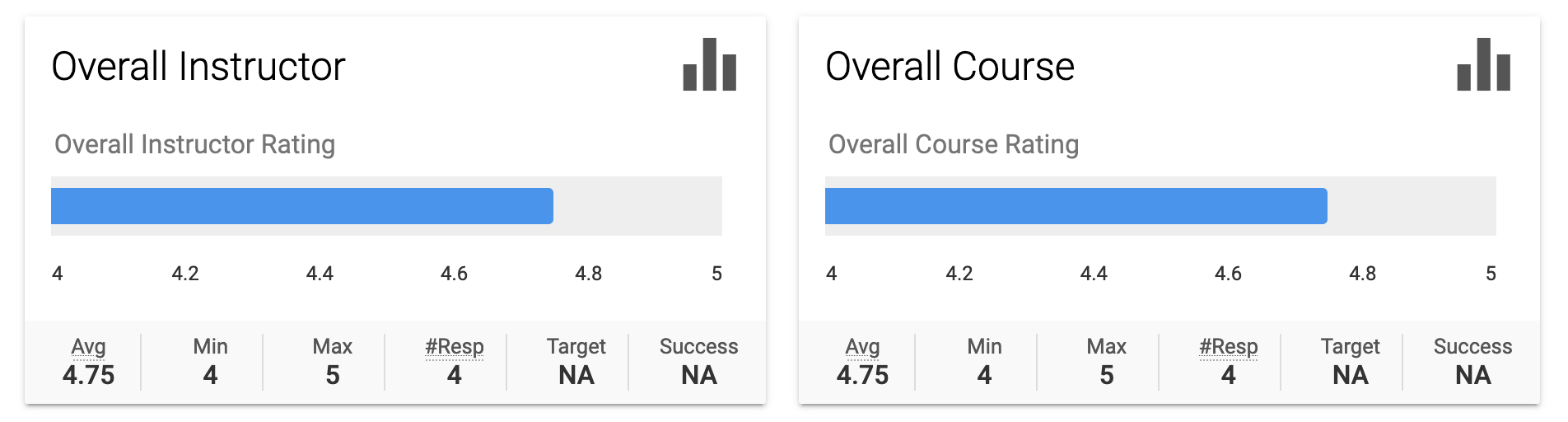
The course has its problems that can and should be improved. One that’s difficult to fix is that students learned RISC-V and then read the CS:APP textbook which uses x86. Right now, they have to map the book examples to RISC-V themselves. The evaluation score is 3.53 for overall instructor and 3.4 for the course, lower than my typical scores (here and here). Seven respondents gave the highest rating, and two the lowest. I appreciate students wrote in the evaluation and in public (here). What’s online is anecdotally true but not complete or comprehensive. My blog is partly to tell the part of the extensive learning that computer science students have accomplished in one of their courses in their four-year journey at Rochester.
Acknowledgements: including but not limited to CS staff Ian Ward and Dave Costello; my TAs Yifan, Boyang, Leo, Jacob, Kestor, Yekai, Zack, and Zachary; and my colleague John Criswell (for suggesting the xargs project).
CSC 253/453 Collaborative Programming and Software Design
Fall 2023 Student Evaluation
Anonymous inputs were collected by the university before the final exam. 9 out of 25 students (36%) submitted the evaluation.
The overall Instructor Rating is 4.89, same as the overall Course Rating.
All nine students gave highest or next highest score to the questions:
Teaching Skills
Rapport with Students
Academic Honesty
Value of the Course
Some of the comments include:
I particularly relished the final big project, which was both challenging and immensely rewarding. Working collaboratively with my team was a highlight, fostering a sense of friendship and shared purpose that made the learning process especially enjoyable. However, I do wish we had more time allocated for this final project. The complexity and scale of the project made it engaging, and having additional time would have allowed us to delve deeper into the coding challenges and explore more creative solutions as a team.
hard course
This course has a strong emphasis on collaboration, which is very helpful for my future work. Project is a little bit hard and it takes a lot of time.
Chen Ding, Professor of Computer Science WFs 3:25pm to 4:40 Gavett 206
CSC 252 teaches the fundamentals of modern computer organization, including software and hardware interfaces, assembly languages and C, memory hierarchy and program optimization, data parallelism and GPUs. It shows the underlying physical reality which the virtual world including AI is built and depends on.
Tangential to CSC 253/453 on software design but fun to explain when there is enough time in a lecture are these two math problems which are general composite properties that can be proved easily using simple building blocks.
Theorem: If a complex value is a root of a polynomial of real-valued coefficients, so is its conjugate.
To prove this for ALL such polynomials, we need just two properties of complex number arithmetic: (1) the conjugate of the sum is the sum of the conjugates, and (2) the conjugate of the product is the product of the conjugates. These are binary operations and can be shown easily. Then for any real-valued polynomial f(x), we have f(~x) = ~f(x) = ~0 = 0, and the theorem is proved.
Theorem: In a triangle, a median is a line from an end point to the center of the opposite side. For any triangle, its three medians meet at one point which is 1/3 the way from the end point to the edge.
To prove this for ALL triangles, we use a property of a single line segment. Let P be a mid-point on the line segment P1P2. Let the (complex-plane) coordinates of P1, P2, P be x, y, z, and the ratio r = P1P / PP2, then we have z = (x + ry) / (1 + r). If we use this equation to compute the coordinate of the 1/3-way point of the three medians, we’ll see that they are identical: 1/3(x1+x2+x3), where xs are the coordinates of the three end-points of the triangle.
Source: An Imaginary Tale — The Story of i, by Paul J. Nahin, Princeton U Press, 1998.
Photo credit: AI generated by Kaave Hosseini for CSC 484 for “dimension reduction”
Chen Ding, Professor of Computer Science MWs 3:25pm to 4:40 Hylan 202
Modern software is complex and more than a single person can fully comprehend. This course teaches collaborative programming which is multi-person construction of software where each person’s contribution is non-trivial and clearly defined and documented. The material to study includes design principles, safe and modular programming in modern programming languages, software teams and development processes, design patterns, and productivity tools. The assignments include collaborative programming and software design and development in teams. The primary programming language taught and used in the assignments is Rust. Students in CSC 453 have additional reading and requirements.
Behavioral Design Patterns: Command, New Type, RAII Guards, Strategy
Creational Design Pattern: Builder
Trait Object and State Pattern
Meta Programming
Logging and Serialization
Software Engineering
Team
Unified Software Development Process
Testing
Code Review
Human Values
Apportionment
Algorithmic Fairness
Fallibility and Truth Seeking
Past Students’ Comments
“Separation of concern is perhaps my favorite topic in software development right now; I love making software as modular and reusable as possible. Taking CSC 253 also helped me to understand the MVC architecture in mobile app development class almost immediately.” (Fall 2022)
“A huge part of the course is graded on a complete group project. You’re assigned a random group, and you better pray to get group members who show up to class and do their parts.” (Feb. 2023)
“The lessons on iterators truly opened my eyes to a whole new world of thinking about programming, and thinking about modules helped me understand the concept of information hiding and team collaboration, and especially communication and just how important it is. I will be bringing my learnings from your class to Seattle this summer for sure!” (Fall 2022)
“The most meaningful part is doing the final project – DVCS in group with other 4 outstanding classmates. In this project, I learned how Git works, how to apply the design principles into practice, and how to collaborate well with others in programming. The reward didn’t show up immediately when and after the class, but afterward when I looked for an SDE job and prepared for the interviews, I was reminded of what I learned in the CSC453 course and found out how useful it is to my career.” (Fall 2021)
On Rust
“Speaking of languages, it’s time to halt starting any new projects in C/C++ and use Rust for those scenarios where a non-GC language is required. For the sake of security and reliability. the industry should declare those languages as deprecated.” – Mark Russinovich, CTO of Microsoft Azure, author of novels Rogue Code, Zero Day and Trojan Horse, Windows Internals, Sysinternals tools, author of novels Rogue Code, Zero Day and Trojan Horse, Windows Internals, Sysinternals tools, 9/19/2022
Logic in Coq. Logical Connectives: Conjunction, Disjunction, Falsehood and Negation, Truth, Logical Equivalence, Logical Equivalence, Existential Quantification. Programming with Propositions. Applying Theorems to Arguments. Coq vs. Set Theory: Functional Extensionality, Propositions vs. Booleans, Classical vs. Constructive Logic.
Inductively Defined Propositions. Induction Principles for Propositions. Induction Over an Inductively Defined Set and an Inductively Defined Proposition.
The Curry-Howard Correspondence. Natural Deduction. Typed Lambda Calculus. Proof Scripts. Quantifiers, Implications, Functions. Logical Connectives as Inductive Types.
Leasing by Learning Access Modes and Architectures (LLAMA) Jonathan Waxman
November 2022
Lease caching and similar technologies yield high performance in both theoretical and practical caching spaces. This thesis proposes a method of lease caching in fixed-size caches that is robust against thrashing, implemented and evaluated in Rust.