CUDA and OpenCL allow the programmer to specify the independence of threads and GPU does not exploit the data locality enabled by this independence. Cedric Nugteren from EindHoven University of Technology analyzed the potential of locality-aware scheduling for GPUs.
They summarized the performance optimizations based on locality for scheduler into the following rules:
(1) threads accessing the same cache line must be grouped in a warp
(2) threads having strong inter-thread locality must be grouped in a single thread block
(3) thread blocks with data-locality should be scheduled on a single core or simultaneously on different cores(temporal locality for shared L2 cache).
(4) minimize pollution of shared caches between the threads executed simultaneously
(5) spread accesses of the simultaneously executed threads as evenly as possible across the memory banks.
And their scheduler assumes all n threads are independent. So the n threads can be reordered as n! distinct sequences. The goal of the scheduler is to find the order which has the minimal execution time.
Experiment:
Setup: GPGPU-Sim 3.2.1
16KB L1 Cache(128 byte Cachelines)
768KB L2 Cache
16 SMs (512 CUDA cores total)
Performance Indicator:
IPC
Benchmark selection:
Integral image (row-wise)
Integral image (column-wise)
11 by 11 convolution
Matrix-multiplication
Matrix copy(per row)
Matrix copy(per column)
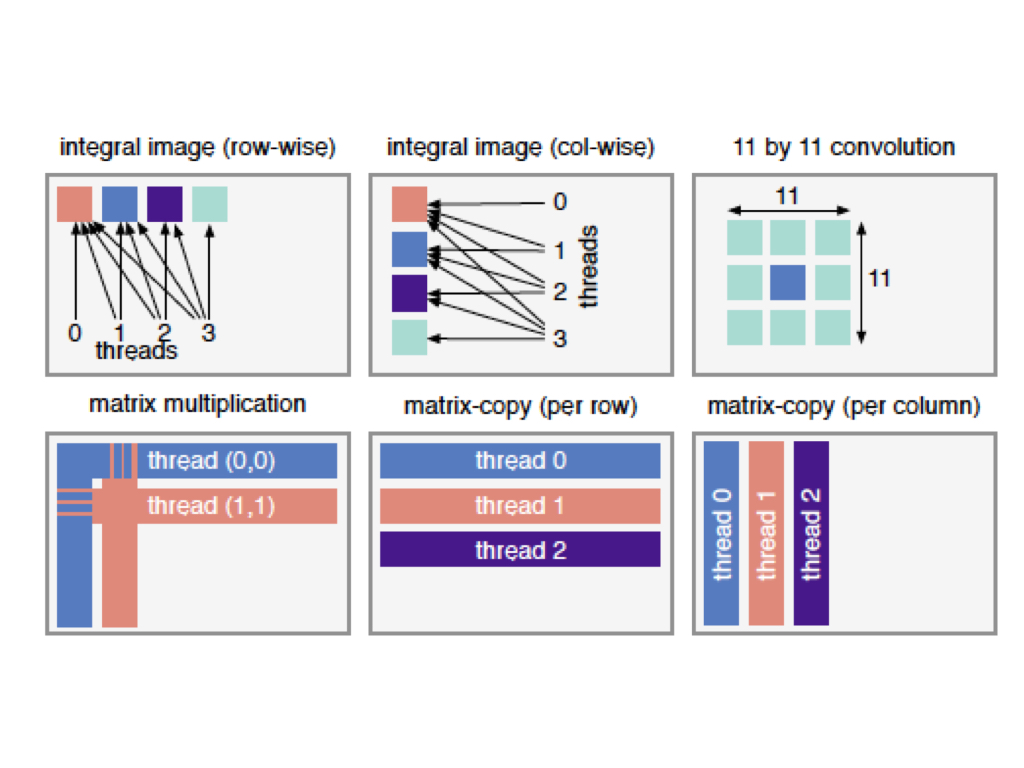
Reordering:
It’s impractical to consider all the reordering sequences for the large number of threads. So only the following scheduling order is considered.
1D reordering
Sequential: unmodified original ordering
Stride(a, b): An ordering with a configurable stride a and granularity b
2D reordering
Zigzag(a,b): An ordering with a configurable stride a and granularity b
Tile(a,b,c): A ordering with configurable row length a, dimensions of the tile (b, c)
Hilbert(a): A ordering with a space filling fractal for (a, a) threads

The experiments consider 2170 schedules by sweep over the above 5 orderings with different parameters and different active thread counts.


Good conclusions to tune GPU programs by hand.